
تقوم نموذج التسجيل في SaaS بجذب 500 مستخدم جديد يوم الثلاثاء. تبدأ سلسلة الإعداد صباح الأربعاء. بحلول يوم الخميس، ارتدت 7 رسائل بريد إلكترونية بشكل كامل — ليس من عناوين مزيفة أو قابلة للتجاهل، بل من "gmial.com" و "yaho.com" و "hotmial.com". هؤلاء المستخدمون السبعة كتبوا بسرعة على الهاتف المحمول، وضغطوا على الإرسال، وانتقلوا. لن يروا أبداً رسالة التفعيل. البعض سيعود، ويلوم المنتج، ويتخلى. الباقي يختفي.
كل خطأ إملائي في البريد الإلكترونى في قمع الالتقاط ينتمي إلى شخص حقيقي أراد الدخول. هذا ليس احتيال. هذا ليس حركة روبوتات. هذا هو 1-3% الهادئ من كل قائمة والذي، وفقاً لتحليل ZeroBounce لأكثر من 4 مليارات عنوان، يظهر كنطاقات تحتوي على أخطاء إملائية — عناوين تمر عبر كل فحص regex، تبدو صحيحة تماماً، وتكسر قمعك بصمت قبل أن تصل أول رسالة إعداد.

جدول المحتويات
- لماذا يعتبر الخطأ الإملائي في البريد الإلكترونى مشكلة مختلفة عن العنوان المزيف أو القابل للتجاهل
- التكلفة الحقيقية للأخطاء الإملائية في البريد الإلكترونى عبر خمسة نماذج أعمال
- أنماط الأخطاء الإملائية الستة التي تمثل معظم العناوين السيئة
- مقارنة طرق الكشف — ما الذي يمسك فعلاً بالأخطاء الإملائية عند الالتقاط
- تدفق تسجيل مقاوم للأخطاء الإملائية في سبعة قرارات
- ما الذي يسأله الممارسون فعلاً بشأن الأخطاء الإملائية في البريد الإلكترونى
لماذا يعتبر الخطأ الإملائي في البريد الإلكترونى مشكلة مختلفة عن العنوان المزيف أو القابل للتجاهل
ابدأ بتصنيف الأشياء، لأن بقية المقالة تعتمد عليه. ثلاثة أنماط فشل تظهر في كل نموذج تسجيل، وتبدو متشابهة في سجلات الارتداد الخاصة بك بينما تتطلب ردود مختلفة تماماً.
عناوين الأخطاء الإملائية هي مستخدمون شرعيون مع أخطاء إدخال ميكانيكية: gmial.com, yaho.com, hotnail.com, outlok.com. الشخص يريد البريد الإلكترونى. يتوقع رابط التفعيل. كتب بسرعة، فقد حرفاً واحداً، وقبل النموذج ذلك. كل مقياس في قمعك سيتعامل معهم كمستخدمين متفاعلين ثم اختفوا في حين أنهم في الواقع مستخدمون لا يمكن الوصول إليهم من البداية.
العناوين القابلة للتجاهل شرعية في الشكل لكن متعمدة في التجنب: mailinator.com, tempmail.io, guerrillamail.com. المستخدم يختار فعلياً عدم الدخول في علاقة مع الظهور باختيار الدخول. يريدون الإصدار التجريبي والمحتوى المحمي والرمز الخصم — وليس رسائل دورة الحياة. يتعامل فاحص البريد الإلكترونى القابل للتجاهل المخصص مع هذه الفئة لأن منطق الكشف هو بشكل أساسي بحث عن سمعة النطاق، وليس حساب القرب.
العناوين غير الصالحة أو المزيفة هي سلاسل قمامة أو نطاقات مختلقة أو تقديمات روبوتات: asdf@asdf.asdf, test@test.test. لا توجد نية بشرية، لا توجد إشارة قابلة للاسترجاع. رفض وتحرك.
هذه تحتاج إلى معاملة مختلفة عند حدود التسجيل. يجب حظر القابل للتجاهل أو خفض مستوى إلى مستوى ضيف. يجب الإشارة إلى الخطأ الإملائي برسالة تصحيح بنقرة واحدة. يجب رفض المزيف برسالة خطأ عامة. معاملتهم كفئة "بريد إلكترونى سيء" واحدة ينتج عنها أحد وضعي الفشل: إما أنك تضيف احتكاكاً للمستخدمين القابلين للاسترجاع بحظرهم بشكل صعب، أو أنت تقبل كل شيء وتمتص ضرر الارتداد لاحقاً. كلاهما مكلف.
السبب في عدم تمكن التحقق من regex من التقاط الأخطاء الإملائية هو هيكلي، وليس خاص بالتنفيذ. يحدد RFC 5321 و RFC 5322 بناء جملة عنوان البريد الإلكترونى — الأحرف المسموحة، قواعد الاقتباس، تنسيق النطاق، حدود الطول. السلسلة "john@gmial.com" متوافقة تماماً مع RFC. صندوق البريد غير موجود؛ النطاق مسجل لدى محتال محاولة اسم النطاق؛ المستخدم لن يستقبل أبداً بايت واحد من خوادمك. لكن السلسلة صحيحة. يعمل Regex على الأحرف، وليس على دقة DNS أو قرب النطاق. هذا هو حد فئة لمطابقة الأنماط، وليس شيئاً يمكنك إصلاحه برسم بياني أفضل.
عنوان الخطأ الإملائي متوافق تماماً مع RFC، صحيح من الناحية النحوية، وغير قابل للتمييز هيكلياً عن عنوان حقيقي — وهذا بالضبط السبب في أن طبقة التحقق الخاصة بك تدعه يمر.
الحجم المخفي أكبر مما تقدره معظم الفرق. يضع مجموعة بيانات ZeroBounce البالغة 4 مليارات عنوان نطاقات الأخطاء الإملائية في نطاق 1-3% من عمليات التقاط نماذج الويب النموذجية. يلاحظ بحث Kickbox الخاص بنطاقات الأخطاء الإملائية أن الجماهير الثقيلة على الهاتف المحمول تميل نحو الطرف الأعلى من هذا النطاق لأن إدخال شاشة اللمس ينتج معدلات خطأ على مستوى الأحرف أعلى من لوحات المفاتيح المادية. بالنسبة إلى SaaS يقوم بـ 10000 تسجيل شهري بمعدل خطأ إملائي 1.5%، يبلغ ذلك 150 مستخدماً كل شهر استبعدوا أنفسهم من كل رسالة بريد إلكترونى تابعة للدورة التي ترسلها — التفعيل وتعليم الميزات والتذكيرات بالفواتير واسترجاع المستخدم.
يتدفق هؤلاء 150 مستخدماً عبر ثلاث قنوات تكاليف لاحقة في نفس الوقت. تعمل سلاسل الإعداد بدون جدوى، مما يجر تحويل التجربة المدفوعة. البريد الإلكترونى المعاملة — إعادة تعيين كلمات المرور والإيصالات ورموز المصادقة الثنائية — لا تصل أبداً، مما ينتج عنه تذاكر دعم بقيمة 5-15 دولار لكل منها. تجمع الحملات التسويقية الارتدادات الصعبة التي تآكل سمعة المرسل عبر كل النطاق، وليس فقط للعناوين التي تحتوي على أخطاء إملائية. مصفوفة التكلفة في القسم التالي تحدد كل قناة لخمسة نماذج أعمال شائعة.
التكلفة الحقيقية للأخطاء الإملائية في البريد الإلكترونى عبر خمسة نماذج أعمال
معدل الخطأ الإملائي 1-3% نفسه ينتج ضرراً بالدولار مختلفاً بشكل كبير حسب ما يفعله البريد الإلكترونى فعلاً في عملك. عميل B2B بخطأ إملائي وعملية دفع للتجارة الإلكترونية بخطأ إملائي تفشلان بطرق مختلفة، على جداول زمنية مختلفة، مقابل خطوط أساس إيرادات مختلفة.
| نموذج العمل | وظيفة البريد الإلكترونى الأساسية المفقودة | تأثير معدل الخطأ الإملائي | التأثير المركب |
|---|---|---|---|
| تجربة SaaS المجانية | التفعيل + سلسلة الإعداد | 1-2% لا تبدأ التجربة | فقدان 15-25% من رفع الإعداد |
| دفع التجارة الإلكترونية | تأكيد الطلب + الشحن | 1-3% يؤدي إلى تذاكر دعم | 5-15 دولار لكل "أين طلبي" |
| النشرة الإخبارية / المحتوى | الترحيب + الحملات الجارية | 1-3% لا تؤكد المشاركة أبداً | الارتداد يقترب من منطقة الخطر 2% |
| توليد عملاء B2B | تنمية العملاء المتوقعين + تسليم المبيعات | 0.5-1.5% (ثقيل سطح المكتب) | فقدان MQL = كامل CAC مهدر |
| تطبيق المستهلك الأول للهاتف المحمول | التحقق من الحساب + إعادة التفاعل | 2-3%+ (انحياز الهاتف المحمول) | يزيد من انخفاض الاحتفاظ بالهاتف المحمول |
مصادر معدل الخطأ الإملائي: تحليل ZeroBounce لـ 4 مليارات عنوان وبحث Kickbox الخاص بنطاقات الأخطاء الإملائية. أرقام رفع الإعداد من تقرير Totango 2023 SaaS Metrics. حدود الارتداد من مؤشرات Mailchimp لتسويق البريد الإلكترونى و ممارسات M3AAWG الشائعة الأفضل للمرسل. معدلات خطأ الهاتف المحمول من بحث Azenkot و Zhai الخاص بإدخال النص في MobileHCI.
SaaS يعاني من أعلى تأثير بالدولار لكل خطأ إملائي لأن التكلفة تتضاعف عبر دورة حياة العميل بأكملها. اسير الرياضيات. تضع معايير Totango رفع سلسلة رسائل البريد الإلكترونى المنظمة عند 15-25% فوق عدم وجود سلسلة. يستقبل المستخدم الذي يحتوي على خطأ إملائي صفر رسائل بريد إلكترونى للإعداد ويعود إلى تحويل خط الأساس. بالنسبة إلى خطة بقيمة 50 دولار شهرياً مع متوسط مدة 12 شهراً، يمثل دلتا تحويل 20 نقطة على كل مستخدم مفقود تقريباً 120 دولار في الإيرادات المتوقعة لكل تسجيل به خطأ إملائي. بـ 10000 تسجيل شهري ومعدل خطأ إملائي 1.5%، يبلغ ذلك 150 مستخدماً × 120 دولار = حوالي 18000 دولار شهرياً من الإيرادات المتوقعة يتم فقدانها بصمت — قبل احتساب التأثيرات الإحالة والتوسع أو الكلام الشفهي.
كل نقطة مئوية من الأخطاء الإملائية غير المكتشفة في نموذج التسجيل الخاص بك هي نقطة مئوية من استثمار الإعداد الخاص بك التي تطلق في فراغ.
التجارة الإلكترونية تدفع عبء العمل الدعم، وليس فقط البريد المفقود. تضع بيانات معيار خدمة العملاء في Zendesk مشاكل المصادقة و "لم أتسلم بريدي الإلكترونى" من بين أعلى فئات التذاكر الواردة، غالباً ما تمثل 15-30% من الحجم الإجمالي. يتتبع حصة ذات مغزى إلى التقاط خطأ إملائي، وليس فشل الاستسلام على جانب المرسل. كتب العميل gmial.com، ارتد تأكيد الطلب بشكل صعب، يفترض العميل أن الطلب فشل، وقائمة التذاكر بـ 5-15 دولار لحلها يدويا.
مرسلو النشرات الإخبارية يواجهون تسلسلات السمعة. عندما ترتد 1-3% من التسجيلات الجديدة بشكل صعب، فأنت تسرع نحو سقف الارتداد لكل حملة يشير Mailchimp إليه كمنطقة خطر قابلية التسليم. الضرر ليس معزولاً عن العناوين التي تحتوي على أخطاء إملائية — تطبق ISPs التصفية على نطاقك الإرسال بالكامل بمجرد أن تتجاوز معدلات الارتداد 2%. يمكن لمجموعة التقاط السيئة واحدة أن تكبت وضع الصندوق الشرعي للحملات الثلاث التالية.
عائد البريد الإلكترونى المرتجع الذي أبلغت عنه جمعية التسويق المباشر 35-42 دولار لكل 1 دولار ينفق (DMA Marketer Email Tracker) يضخم حساب التكلفة. حتى نسب صغيرة من الرسائل التي لم يتم توصيلها تتضاعف مقابل نسبة الرافعة هذه. معدل خطأ إملائي 1.5% ليس خسارة إيرادات 1.5% — إنه 1.5% من استثمار الإرسال الخاص بك ينتج صفر ناتج بينما تنتج 98.5% المتبقية العائد المنشور. عدم التناسب هو ما يجعل الأخطاء الإملائية جديرة بالإصلاح بشكل خاص بالنسبة لحجمها الظاهري.
أنماط الأخطاء الإملائية الستة التي تمثل معظم العناوين السيئة
الأخطاء الإملائية ليست عشوائية. يتجمعون في حفنة من الأنماط الميكانيكية المدفوعة بتخطيط لوحة المفاتيح وسلوك التصحيح التلقائي للهاتف المحمول والاختصارات المعرفية المتوقعة. معرفة الآلية وراء كل نمط تخبرك ما الذي يمكن تصحيحه بشكل حتمي مقابل ما يحتاج تأكيد المستخدم.
- أخطاء إملائية بقرب على مستوى النطاق (gmial, yhoo, hotnail). هذه تتبع مجاورة لوحة المفاتيح QWERTY — يجلس "i" و "a" بجانب بعضهما على صف الرئيس، ينزلق إصبع السبابة، يقبل النموذج النتيجة. تحدد ZeroBounce هذه كأكبر فئة خطأ إملائي واحد في مجموعة بيانات 4 مليارات عنوان. هي أيضاً الأكثر قابلية للاسترجاع: فاصلة Levenshtein للنطاق الصحيح هو 1، المطابقة الغامضة مقابل قائمة قصيرة من موفري الخدمات الكبار تمسك بها بدقة عالية.
- التحويل الخاص بـ TLD (.co vs .com, .net vs .com, .om vs .com). مدفوعة بلوحات مفاتيح الهاتف المحمول حيث ".com" مفتاح اختصار واحد يمكن تفويته، وبواسطة المستخدمين في الأسواق ذات النطاقات النشطة برموز البلد (.co.uk, .com.au) الذين يكتبون ذاكرة العضلات الخاصة بهم بطريقة خاطئة. ضار بشكل خاص لأن ".co" بحد ذاته نطاق صحيح مخصص لكولومبيا. فحوصات وجود النطاق تمر بنظافة. صندوق البريد بالتأكيد غير موجود تقريباً.
- مقايضات النطاق الفرعي والموفر (outlook.com ↔ live.com, icloud ↔ icould, msn ↔ mns). يساء تذكر المستخدمون لنطاق Microsoft أو Apple أي حساب لديهم، خاصة بعد الهجرات. انتشار أعلى في الفئات العمرية الأقدم حيث حدث التسجيل الأصلي على موفر قديم. المطابقة الغامضة مقابل سجل نطاق خطأ إملائي تمسك بها؛ regex لا تفعل.
- أحرف مضاعفة أو مسقطة (aaccount, coom, gmaill, hotmai). عناصر ملء بيانات شاشة اللمس. وثائق بحث إدخال النص Azenkot و Zhai معدلات خطأ على مستوى الأحرف أعلى بشكل منهجي على شاشات اللمس مقارنة بلوحات المفاتيح، خاصة بالنسبة للسلاسل التي لا يراجعها المستخدمون بصرياً قبل الإرسال. حقول البريد الإلكترونى عالية الخطورة لأنها طويلة وغير قاموسية وكثيفة بصرياً.
- تجاوزات التصحيح التلقائي للهاتف المحمول. النص التنبئي يصحح بصمت "تصحيح" شظايا البريد الإلكترونى الصحيحة إلى كلمات قاموس شائعة ("gmail" → "gail," "outlook" → "outlooks"). الإصلاح هيكلي بدلاً من المحقق: يجب أن تعلن حقول الإدخال
type="email"وautocomplete="email"لتعطيل التصحيح التلقائي على مستوى نظام التشغيل. تتعامل إرشادات تصميم النماذج لمجموعة Nielsen Norman مع هذا كممارسة أساسية لأي حقل عالي الخطورة. - المسافة البيضاء والانزلاقات بالعلامات الترقيمية (مسافة زائدة، فاصلة بدلاً من النقطة، @ مضاعف). غالباً ما تكون غير مرئية للمستخدم لأن حقل النموذج يقص العرض بصرياً، مما يخفي المشكلة حتى يرفضها SMTP العنوان. تم حذف منطق التطبيع عند الالتقاط يلغي المجموعة القابلة للاسترجاع؛ يحتاج الباقي التحقق الصريح مقابل نحو العنوان.
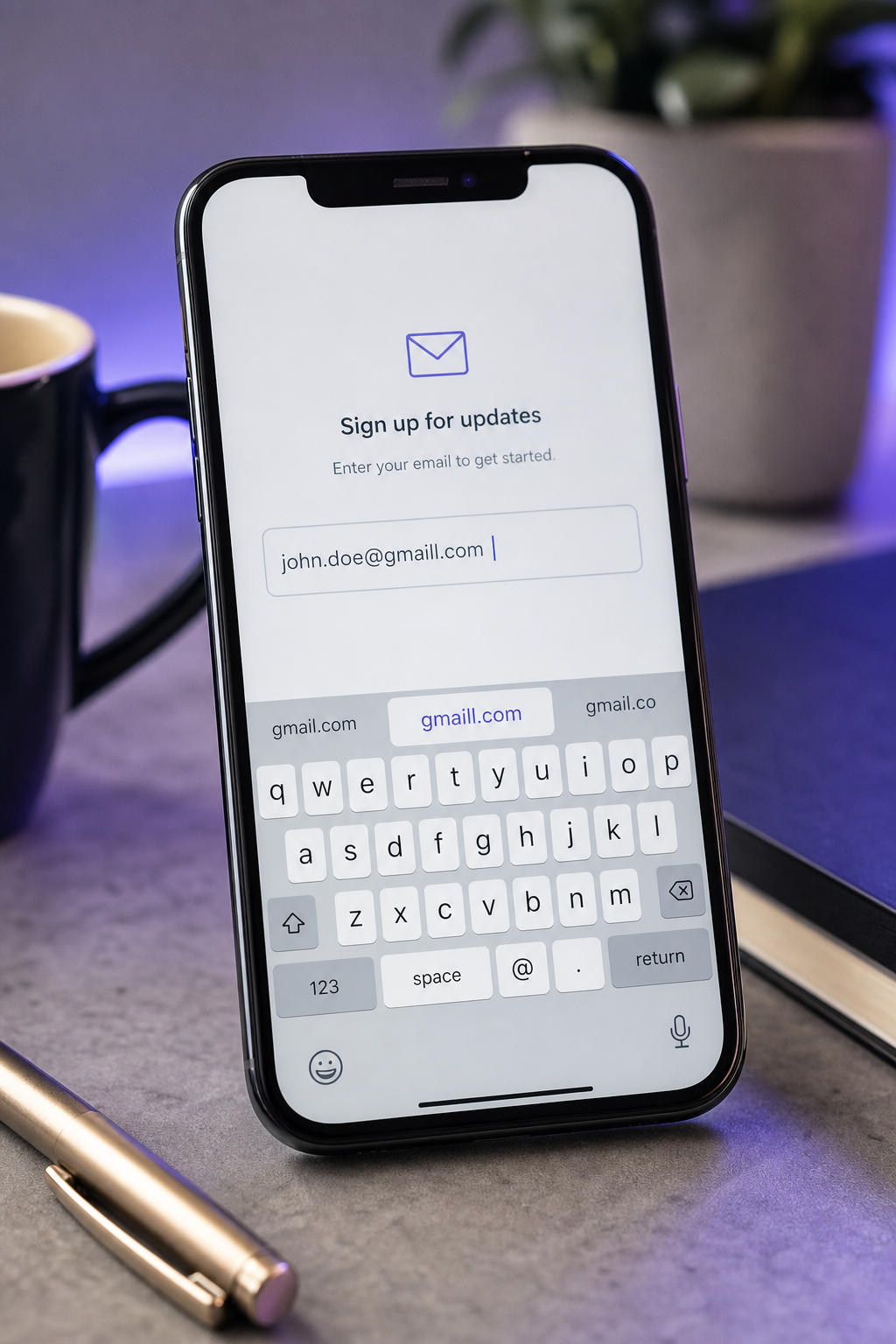
من بين هذه الأنماط الستة، ثلاثة قابلة للتصحيح بشكل حتمي من السلسلة العنوان وحدها (القرب، TLD، أحرف مضاعفة)، اثنان يتطلبان تأكيد المستخدم لأنهما غامضان (مقايضات النطاق الفرعي، تجاوزات التصحيح التلقائي)، وواحد يتم منعه مسبقاً عند طبقة الإدخال قبل أي تحقق يعمل (مسافة بيضاء). خريطة العلاج مهمة لأنها تعين عقد UX: أي الأنماط تستحق التطبيع الصامت، وأي تستحق رسالة "هل تقصد؟" وأي تستحق الحظر برسالة خطأ.
مقارنة طرق الكشف — ما الذي يمسك فعلاً بالأخطاء الإملائية عند الالتقاط
معظم الفرق لديها شيء ما التحقق من حقل البريد الإلكترونى الخاص بها. السؤال هو ما إذا كان ما لديهم يمسك فعلاً بفئة الخطأ الإملائي بدلاً من فئة بناء الجملة. الطرق الخمس أدناه تغطي فضاء الخيارات الواقعي.
| الطريقة | تمسك بالأخطاء الإملائية | الوقت الفعلي | الاحتكاك المضاف | تأثير القائمة |
|---|---|---|---|---|
| فحص بناء الجملة Regex / RFC | لا | نعم | لا شيء | لا شيء |
| تأكيد الاشتراك المزدوج | بعد الارتداد | لا (غير متزامن) | مرتفع | انكماش 20-40% |
| مطابقة غامضة من جانب العميل | جزئي | نعم | منخفض | قليل |
| فحص سجل MX للنطاق | لا | نعم | لا شيء | منخفض |
| API التحقق في الوقت الفعلي | نعم | نعم (أقل من 500 ميلي ثانية) | قليل | قليل |
شكل انكماش الاشتراك المزدوج: دراسة GetResponse أحادي مقابل مزدوج للاشتراك. زمن انتظار API الفعلي: وثائق NeverBounce API. هندسة معمارية للتحقق ثلاثي الطبقات (بناء الجملة → MX → صندوق بريد): وثائق ZeroBounce API.
Regex ضروري لكن غير كافي. ينفذ RFC 5321 و 5322 بنظافة، يحجب السلاسل المشوهة الواضحة، ويعمل في وقت الصفر على العميل. كل عنوان خطأ إملائي نوقش سابقاً يمر عبر regex دون فتور. عامل regex باعتباره أول مرشح لك، أبداً كمرشح وحيد.
الاشتراك المزدوج هو "الحل" الأكثر شعبية والأكثر تكلفة. وجدت دراسة GetResponse أن قوائم الاشتراك المزدوج كانت 20-40% أصغر من قوائم الاشتراك الفردي — والمستخدمون الذين يحتويون على أخطاء إملائية مضمونون رياضياً أن يكونوا في 20-40% المفقود لأنهم لا يستطيعون استقبال رسالة التأكيد بالتعريف. الآلية معكوسة: رسائل التأكيد تشخص مشكلة الخطأ الإملائي فقط بعد أن يكون المستخدم مفقوداً بالفعل. تكتشف الخطأ الإملائي عندما تقفز رسالة التأكيد نفسها، وفي هذه المرحلة أغلق المستخدم علامة التبويب وانتقل. لا يزال الاشتراك المزدوج له قيمة للتصريح والتصفية. ليس، بأي معنى مهم، طبقة كشف خطأ إملائي.

المطابقة الغامضة من جانب العميل ("هل تقصد gmail.com؟") هي UX جيدة، هشة كبنية أساسية. يتطلب الحفاظ على قاموس نطاق الخطأ الإملائي والتعامل مع النطاقات الدولية وتجنب نمط الفشل الموثق من قبل معهد Baymard التي تم وضع علم عليها نطاقات رموز البلد الشرعية أو NTLDs بالشركة كأخطاء إملائية. القاموس عمره. أنماط خطأ إملائي جديدة تظهر. مفيد كطبقة واجهة المستخدم على أعلى استدعاء التحقق الحقيقي. ليس بديلاً لواحدة.
فحوصات سجل MX تحكم خارج النطاقات غير الموجودة لكن تفوت حالات خطأ إملائي للنطاق الحقيقي. "gmial.com" هو نطاق مسجل بدقة MX — وهذا بالضبط السبب في أنه فخ خطأ إملائي طويل الأمد. يريد المحتال الحركة. فحوصات MX تمسك بنطاقات مختلقة؛ لا تمسك بفئة الخطأ الإملائي التي تتحدث عنها هذه المقالة. الفحص رخيص ويستحق الجري، لكن لا تخطئ بتمريره كعنوان حقيقي.
API التحقق في الوقت الفعلي يجمع بين جميع الطبقات الأربع. الهندسة المعمارية المعيارية الموثقة من قبل ZeroBounce و NeverBounce تشغل بناء الجملة → MX → صندوق بريد مستوى التحقيق → علم نطاق الخطأ الإملائي → علم نطاق قابل للتجاهل في استدعاء فردي أقل من 500 ميلي ثانية. الإخراج ليس ثنائي pass/fail؛ إنه حكم مصنف يمكن لتدفق التسجيل الفرع عليه بشكل مختلف لكل فئة. استدعاء التحقق من عنوان البريد الإلكترونى في الوقت الفعلي يعيد هذه الإشارات كرموز نتيجة منفصلة، وهذا ما يسمح لك بالاقتراح من أجل الأخطاء الإملائية وحجب من أجل القابلة للتجاهل ورفض من أجل invalids دون كتابة خمسة مدققين مستقلين.
الكمون ليس اعتراضاً. أوقات الاستجابة المنشورة 100-500 ميلي ثانية الخاصة بـ NeverBounce أقل من الحد الحسي لتأخر واجهة المستخدم، خاصة عندما ينار الاستدعاء في ضبابية الحقل بدلاً من الإرسال. كان المستخدمون قد نقلوا اهتمامهم بالفعل إلى الحقل التالي؛ تظهر الاقتراحات عندما يعودون للنظر.
تدفق تسجيل مقاوم للأخطاء الإملائية في سبعة قرارات
الهندسة المعمارية أدناه تكتيكية وليس نظرية. كل عنصر هو قرار تتخذه الفريق مرة واحدة ويشفره في مسار كود التسجيل. المنطق يهم أكثر من بناء الجملة المحدد — التكيف مع المكدس الخاص بك.
- التحقق عند الضبابية، وليس فقط عند الإرسال. شغل استدعاء التحقق عندما يفقد حقل البريد الإلكترونى التركيز حتى تظهر رسالة الاقتراح قبل أن يلتزم المستخدم عقلياً بالحقل التالي. يظهر بحث نموذج Nielsen Norman Group التحقق المضمن يتفوق على التحقق من وقت الإرسال لاسترجاع الخطأ لأن المستخدم لا يزال موجهاً إلى الحقل الذي غادره للتو. أخطاء وقت الإرسال تتطلب إعادة التوجيه والشعور بالعقاب.
- استخدم رد استجابة API مصنف بالحكم، وليس منطقياً. يجب أن تفصل الاستجابة بين الخطأ الإملائي والقابل للتجاهل وحساب الدور وأعلام صندوق البريد غير الصالح حتى يمكن لكل منها تشغيل واجهة مستخدم مختلفة. إن إجابات "is_valid" المنطقية تجبرك على اختيار معاملة واحدة لخمس مشاكل مختلفة، وهذا هو كيف تنتهي الفرق بحجب المستخدمين القابلين للاسترجاع. واجهات برمجة تطبيقات البائع تنظم الردود بهذه الطريقة لسبب ما.
- اقترح، لا تصحح تلقائياً. لأعلام الخطأ الإملائي، اعرض "هل تقصد john@gmail.com؟" كقبول بنقرة واحدة. التصحيح التلقائي الصامت ينتهك ثقة المستخدم — يظهر بحث نموذج Baymard للتجارة الإلكترونية أن المستخدمين يتخلون عندما يمسكون بحقل يتغير تحتهم — ويكسر الحالات الحدودية الشرعية مثل النطاقات الشركاتية التي تبدو وكأنها أخطاء إملائية لكنها ليست كذلك.
- الحظر القابل للتجاهل بشكل منفصل عن الخطأ الإملائي. إشارة قابلة للتجاهل تستحق حظر صعب أو تدهور إلى حساب مستوى الضيف مع ميزات محدودة. إشارة خطأ إملائي تستحق اقتراح ناعم مع إصلاح بنقرة واحدة. معاملة كليهما بالطريقة نفسها يعاقب المستخدمين القابلين للاسترجاع بينما يحمي دون الحماية من سوء استخدام التجربة. تكلفة التفريع هي شرط إضافي واحد.
- تعطيل التصحيح التلقائي على طبقة الإدخال. استخدم
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">. هذا يمنع مسبقاً نمط تجاوز التصحيح التلقائي قبل أي تحقق يعمل. إنه تغيير خمس سمات يلغي فئة خطأ إملائي بأكملها. - عين حدود الارتداد الصعب والآلة الموسيقية عليها. ينصح M3AAWG و Mailchimp بأن تبقى الارتدادات الصعبة الكلية أقل من 1% لكل حملة، مع كون 2% منطقة الخطر. نبه على معدلات ارتداد مجموعة التسجيل أعلى من 1.5% — ليس فقط معدلات على مستوى الحملة بأكملها. ارتداد مستوى المجموعة هو مؤشر رائد بأن التحقق على جانب الالتقاط الخاص بك يفشل لمصدر محدد، والذي ستخفف متوسطات الحملة على مستوى العالم.
- سجل أنماط الخطأ الإملائي وأعدها. تتبع النطاقات التي يخطئها مستخدموك في كثير من الأحيان. إذا كانت جماهيرك ينتجان نمط "yaho.com" أو ".cm" متكرر، فأنت تعرف الآن حيث تقسي منطق الاقتراح. يغلق هذا الحلقة بين كشف وقت الالتقاط والبصيرة الصحية على مستوى القائمة الجارية — ويسمح لك بقياس الدلتا الفعلي من كل تغيير التحقق بدلاً من التخمين.

يأخذ التدفق ككل تكامل API واحد وحفنة من قرارات واجهة المستخدم. الفائدة المركبة هي أن كل نظام لاحق — الإعداد والفواتير والدعم والتسويق — يعمل على عناوين التي تم مسحها بالفعل عبر الخطأ الإملائي والقابل للتجاهل وعوامل المرشحات غير الصحيحة عند الحد. تتوقف عن تشخيص مشاكل جودة القائمة في لوحات المعلومات وتبدأ منعها عند النموذج.
ما الذي يسأله الممارسون فعلاً بشأن الأخطاء الإملائية في البريد الإلكترونى
- ألا تمسك رسالة البريد الإلكترونى الأكيدة بالأخطاء الإملائية بالفعل؟ لا — إنها تشخصها، لا تمسك بها. وجدت مقارنة GetResponse أحادي مقابل مزدوج للاشتراك أن 20-40% من المستخدمين أبداً تأكيد، والمستخدمون الذين يحتويون على أخطاء إملائية مضمونون رياضياً في المجموعة المفقودة لأنهم لا يمكنهم استقبال التأكيد بالتعريف. تتعلم الخطأ الإملائي فقط عندما تنجح رسالة التأكيد نفسها، وبحلول هذا الوقت أغلق المستخدم علامة التبويب وانتقل. التحقق من عنوان البريد الإلكترونى في الوقت الفعلي على جانب الالتقاط ينقل الخطأ الإملائي بينما لا يزال المستخدم على النموذج ويمكنه إصلاحه بنقرة واحدة. تبقى رسائل التأكيد ذات قيمة للتصريح والتصفية — إنها تثبت أن المستخدم أراد فعلاً استقبال بريدك. ليسوا، بشكل ميكانيكي، بديلاً عن كشف الخطأ الإملائي عند الالتقاط. تقوم الطبقتان بأعمال مختلفة ويجب أن تتعايش.
- إذا قمت بـ "تصحيح تلقائي" "gmial" إلى "gmail"، هل أنا أتجاوز نية المستخدم؟ أنت تصحح خطأ إدخال ميكانيكي، وليس اختيار مقصود — لكن فقط إذا أكدت مع المستخدم. يظهر بحث نموذج معهد Baymard للتجارة الإلكترونية التصحيحات الصامتة تضر الثقة وتكسر الحالات الحدودية، خاصة النطاقات الشركاتية والنطاقات الإقليمية التي تبدو وكأنها أخطاء إملائية لكنها ليست كذلك (.co كولومبيا، .om سلطنة عمان). نمط مدافع هو اقتراح بنقرة واحدة: "هل تقصد john@gmail.com؟ [نعم، استخدم هذا] [لا، احتفظ بلدي]". يحافظ هذا على وكالة المستخدم بينما يجعل التصحيح بدون احتكاك. يحتفظ المستخدم بالقرار النهائي، يحصل العنوان الذي يحتوي على خطأ إملائي على استرجاع في 95%+ من الحالات حيث يكون الاقتراح صحيحاً، والحالة الحدودية النادرة الشرعية لها مسار تجاوز نظيف. الأسوار الصامتة تحسن المقياس الخاطئ وتنتج تجربة أسوأ للذيل الطويل.
- ما هو الفرق بين عنوان الخطأ الإملائي والعنوان القابل للتجاهل — ولماذا يهم؟ خطأ إملائي هو مستخدم شرعي مع خطأ ميكانيكي؛ قابل للتجاهل هو مستخدم يتجنب فعلياً علاقة. تتداخل الإشارات في المصب — كلاهما ينتج عن الارتدادات، كلاهما يقلل جودة القائمة، كلاهما يضر قابلية التسليم — لكن الاستجابة عند الالتقاط يجب أن تختلف. الأخطاء الإملائية تحصل على رسالة اقتراح لأن المستخدم يريد الدخول. القابلة للتجاهل يحصل على حظر أو تدهور لأن المستخدم يختار الخروج مع الظهور بالدخول. API في الوقت الفعلي التي تعرضها بشكل منفصل يسمح لك بتوجيه كل واحد بشكل مناسب دون كتابة مدققين متوازيين. معاملتهم بشكل متطابق إما على حجب فوق الحد من المستخدمين القابلين للاسترجاع (إذا رفضت أخطاء إملائية مع قابلة للتجاهل) أو حماية أقل (إذا حذرت فقط قابلة للتجاهل مع أخطاء إملائية). فاحص البريد الإلكترونى القابل للتجاهل المخصص يتعامل مع طبقة كشف القابل للتجاهل المحددة؛ طبقة اقتراح الخطأ الإملائي تجلس على القمة.
- كم عدد التسجيلات الخاصة بي التي تحتوي على أخطاء إملائية بالفعل؟ بيانات الصناعة تتقارب في 0.5-2% لجماهير B2B الثقيلة على سطح المكتب و 2-3%+ لتطبيقات المستهلك الثقيلة على الهاتف المحمول، مع مجموعة بيانات ZeroBounce البالغة 4 مليارات عنوان وبحث Kickbox الخاص بنطاقات الأخطاء الإملائية كمصدرين الأكثر استشهاداً. لقياس خط الأساس الخاص بك بدلاً من التخمين: اسحب آخر 90 يوماً من التسجيلات، والمرجع المتقاطع مقابل سجل الارتداد الصعب في ESP الخاص بك، وعزل الارتدادات حيث يكون النطاق حرف Levenshtein واحد متوقفاً عن موفر رئيسي (gmail و yahoo و hotmail و outlook و icloud و aol). تلك المجموعة الفرعية هي معدل الخطأ الإملائي الحالي. قم بتشغيل الاستعلام نفسه مرة أخرى بعد 30 يوماً من نشر التحقق في الوقت الفعلي لقياس دلتا بنظافة. أرقام قبل / بعد هي الأرقام الوحيدة التي تهم لتبرير التكامل داخلياً.
- هل يمكنني بناء كشف الخطأ الإملائي بنفسي بدون API؟ جزئياً. نص مطابقة غامضة من جانب العميل مقابل قائمة ثابتة من نطاقات الأخطاء الإملائية الشائعة (gmial.com, yaho.com, hotnail.com, outlok.com, icould.com) يمسك أعلى 60-70% من الحالات بتكلفة منخفضة — Levenshtein المسافة ≤ 2 مقابل قائمة من 20 موفر رئيسي تغطي حصة مفاجئة من الحجم. تتطلب الحالات المتبقية البنية الأساسية: التعامل مع التحويل TLD وكشف مقايضة النطاق الفرعي واختبارات صندوق البريد غير الموجودة على مستوى SMTP وسجل نطاق خطأ إملائي محدث بشكل مستمر مع ظهور أنماط جديدة. حد البناء مقابل الشراء هو عادة ما إذا كانت فريقك تريد امتلاك صيانة القاموس وبنية التحقق من MX واختبارات صندوق بريد SMTP في الأبد. بالنسبة لمعظم الفرق، مسار API أرخص من الحمل الصيانة، والحصول على تغطية هامشية على الأنماط الذيل الطويل هو حيث يعيش الدخل الفعلي — وليس في أعلى 60% يتعامل معها أي نص لائق في اليوم الأول.