
Un modulo di iscrizione SaaS cattura 500 nuovi utenti martedì. La sequenza di onboarding si avvia mercoledì mattina. Entro giovedì, 7 email hanno rimbalzato duramente — non da indirizzi falsi o temporanei, ma da "gmial.com," "yaho.com," "hotmial.com." Questi 7 utenti hanno digitato velocemente su dispositivo mobile, hanno inviato, sono andati avanti. Non vedranno mai l'email di attivazione. Alcuni torneranno, daranno la colpa al prodotto e abbandoneranno. Il resto scomparirà.
Ogni errore di digitazione in un email nel tuo funnel di acquisizione appartiene a una persona reale che voleva entrare. Non è una frode. Non è traffico bot. È il silenzioso 1–3% di ogni lista che, secondo l'analisi di ZeroBounce su oltre 4 miliardi di indirizzi, si presenta come domini con errori di digitazione — indirizzi che superano ogni controllo regex, sembrano perfettamente validi e interrompono silenziosamente il tuo funnel prima che arrivi la prima email di onboarding.

Indice dei contenuti
- Perché un errore di digitazione email è un problema diverso da un indirizzo falso o temporaneo
- Il costo reale degli errori di digitazione email in cinque modelli di business
- I sei modelli di errore di digitazione che rappresentano la maggior parte degli indirizzi errati
- Metodi di rilevamento confrontati — Cosa cattura effettivamente gli errori di digitazione al momento dell'acquisizione
- Un flusso di registrazione resistente agli errori di digitazione in sette decisioni
- Quello che i professionisti chiedono effettivamente sui errori di digitazione email
Perché un errore di digitazione email è un problema diverso da un indirizzo falso o temporaneo
Inizia dalla tassonomia, perché il resto dell'articolo dipende da essa. Tre modalità di fallimento compaiono in ogni modulo di iscrizione e sembrano simili nei tuoi log di rimbalzo mentre richiedono risposte completamente diverse.
Gli indirizzi con errori di digitazione sono utenti legittimi con errori di input meccanici: gmial.com, yaho.com, hotnail.com, outlok.com. La persona vuole l'email. Si aspetta il link di attivazione. Ha digitato velocemente, ha sbagliato per un carattere, e il modulo l'ha accettato. Ogni metrica nel tuo funnel li tratterà come utenti impegnati-poi-scomparsi quando in realtà sono utenti non raggiungibili-fin-dall'inizio.
Gli indirizzi temporanei sono legittimi nel formato ma intenzionali nell'evitamento: mailinator.com, tempmail.io, guerrillamail.com. L'utente sta attivamente rinunciando a una relazione mentre sembra rinunciare. Vogliono la prova, il contenuto gated, il codice sconto — non la messaggistica del ciclo di vita. Un checker dedicato per indirizzi email temporanei gestisce questa categoria perché la logica di rilevamento è fondamentalmente una ricerca di reputazione del dominio, non un calcolo di prossimità.
Gli indirizzi non validi o falsi sono stringhe spazzatura, domini inventati o inviamenti bot: asdf@asdf.asdf, test@test.test. Nessun intento umano, nessun segnale recuperabile. Rifiuta e vai avanti.
Questi necessitano di un trattamento diverso al confine di registrazione. Un temporaneo dovrebbe essere bloccato o degradato a un livello ospite. Un errore di digitazione dovrebbe essere segnalato con un prompt di correzione con un clic. Un falso dovrebbe essere rifiutato con un messaggio di errore generico. Trattarli come una singola categoria "email cattiva" produce una delle due modalità di fallimento: o aggiungi attrito agli utenti recuperabili bloccandoli duramente, oppure accetti tutto e assorbi il danno da rimbalzo a valle. Entrambi sono costosi.
Il motivo per cui la convalida regex non può catturare gli errori di digitazione è strutturale, non specifico dell'implementazione. RFC 5321 e RFC 5322 definiscono la sintassi di un indirizzo email — caratteri consentiti, regole di quotazione, formato del dominio, limiti di lunghezza. La stringa "john@gmial.com" è completamente conforme a RFC. La cassetta postale non esiste; il dominio è registrato a un typo-squatter; l'utente non riceverà mai un singolo byte dai tuoi server. Ma la stringa è valida. Regex opera su caratteri, non su risoluzione DNS o prossimità del dominio. Questo è un limite di categoria del pattern matching, non qualcosa che puoi correggere con un pattern migliore.
Un indirizzo con errore di digitazione è completamente conforme a RFC, sintatticamente perfetto e strutturalmente indistinguibile da uno reale — che è esattamente il motivo per cui il tuo livello di convalida lo sta lasciando passare.
Il volume nascosto è più grande di quanto la maggior parte dei team stimi. Il dataset di 4 miliardi di indirizzi di ZeroBounce posiziona i domini con errori di digitazione nella fascia 1–3% delle acquisizioni tipiche da moduli web. La ricerca su domini con errori di digitazione di Kickbox nota che i tipi di pubblico mobile-heavy si allineano verso l'estremità superiore di quella fascia perché l'input da touchscreen produce tassi di errore a livello di carattere più elevati rispetto alle tastiere fisiche. Per un SaaS che effettua 10.000 iscrizioni al mese con un tasso di errore di digitazione del 1,5%, sono 150 utenti ogni mese che si sono auto-squalificati da ogni email del ciclo di vita che invii — attivazione, educazione delle funzionalità, promemoria di fatturazione, win-back.
Questi 150 utenti fluiscono attraverso tre canali di costo a valle simultaneamente. Le sequenze di onboarding si attivano nel vuoto, trascinando la conversione da prova a pagamento. La posta transazionale — ripristini password, ricevute, codici a due fattori — non arriva mai, generando ticket di supporto a $5–15 ciascuno. Le campagne di marketing accumulano rimbalzi duri che erodono la reputazione del mittente su tutto il dominio, non solo per gli indirizzi con errori di digitazione. La matrice dei costi nella sezione successiva quantifica ogni canale per cinque modelli di business comuni.
Il costo reale degli errori di digitazione email in cinque modelli di business
Lo stesso tasso di errore di digitazione 1–3% produce danni in dollari drammaticamente diversi a seconda di cosa fa effettivamente l'email nel tuo business. Un lead B2B con errore di digitazione e un checkout di e-commerce con errore di digitazione falliscono in modi diversi, su timeline diversi, rispetto a baseline di ricavi diversi.
| Modello di business | Funzione email primaria persa | Impatto del tasso di errore di digitazione | Effetto composto |
|---|---|---|---|
| Prova gratuita SaaS | Attivazione + sequenza di onboarding | 1–2% non avvia mai la prova | 15–25% onboarding lift perso |
| Checkout e-commerce | Conferma ordine + spedizione | 1–3% attiva ticket di supporto | $5–15 per "dov'è il mio ordine" |
| Newsletter / contenuto | Benvenuto + campagne in corso | 1–3% non conferma mai l'impegno | Il rimbalzo si avvicina alla zona di pericolo 2% |
| Generazione di lead B2B | Nutrizione del lead + handoff di vendita | 0.5–1.5% (desktop-heavy) | MQL perso = CAC completo sprecato |
| App consumer mobile-first | Verifica account + re-engagement | 2–3%+ (mobile skew) | Si compone con il basso retention mobile |
Fonti del tasso di errore di digitazione: analisi di 4 miliardi di indirizzi ZeroBounce e ricerca su domini con errori di digitazione Kickbox. Figure di onboarding lift dal Rapporto 2023 SaaS Metrics di Totango. Soglie di rimbalzo da benchmark di deliverability di Mailchimp e M3AAWG Sender Best Common Practices. Tassi di errore mobile da ricerca su text-entry MobileHCI di Azenkot e Zhai.
SaaS soffre l'impatto più alto di dollari per errore di digitazione perché il costo si compone su tutto il ciclo di vita del cliente. Cammina attraverso la matematica. I benchmark di Totango collocano il lift da una sequenza di email di onboarding strutturata a 15–25% rispetto a nessuna sequenza. Un utente con errore di digitazione riceve zero email di onboarding e ritorna alla conversione di base. Per un piano a $50/mese con una permanenza media di 12 mesi, un delta di conversione di 20 punti su ogni utente perso rappresenta approssimativamente $120 in ricavi previsti per iscrizione con errore di digitazione. Con 10.000 iscrizioni al mese e un tasso di errore di digitazione del 1,5%, sono 150 utenti × $120 = circa $18.000 al mese in ricavi previsti silenziosamente persi — prima di contare gli effetti di referral, espansione o passaparola.
Ogni punto percentuale di errori di digitazione non rilevati nel tuo modulo di iscrizione è un punto percentuale del tuo investimento di onboarding che si attiva nel vuoto.
L'e-commerce paga in carico di supporto, non solo in posta persa. I dati di benchmark del servizio clienti di Zendesk collocano l'autenticazione e i problemi "Non ho ricevuto la mia email" tra le categorie principali di ticket in entrata, rappresentando frequentemente il 15–30% del volume totale. Una quota significativa risale all'acquisizione con errore di digitazione, non al fallimento di deliverability dal lato del mittente. Il cliente ha digitato gmial.com, la conferma dell'ordine ha rimbalzato duramente, il cliente presume che l'ordine sia fallito, e il ticket si mette in coda a $5–15 per risolvere manualmente.
I mittenti di newsletter affrontano cascate di reputazione. Quando l'1–3% delle nuove iscrizioni rimbalza duramente, acceleri verso il limite di rimbalzo per campagna che Mailchimp contrassegna come zona di pericolo di deliverability. Il danno non è isolato agli indirizzi con errore di digitazione — gli ISP applicano il filtro a tutto il tuo dominio di invio una volta che i tassi di rimbalzo si sostengono sopra il 2%. Una cattiva coorte di acquisizione può sopprimere il posizionamento in inbox legittimo per le prossime tre campagne.
L'ROI email segnalato dalla DMA di $35–$42 per $1 speso (DMA Marketer Email Tracker) amplifica il calcolo dei costi. Anche piccole percentuali di email non consegnate si moltiplicano contro quel rapporto di leva. Un tasso di errore di digitazione dell'1,5% non è una perdita di ricavi del 1,5% — è il 1,5% del tuo investimento di invio che produce zero output mentre il rimanente 98,5% produce l'ROI pubblicato. L'asimmetria è quello che rende gli errori di digitazione particolarmente degni di essere corretti rispetto alle loro dimensioni apparenti.
I sei modelli di errore di digitazione che rappresentano la maggior parte degli indirizzi errati
Gli errori di digitazione non sono casuali. Si raggruppano in una manciata di modelli meccanici guidati dal layout della tastiera, dal comportamento dell'autocorrezione mobile e da scorciatoie cognitive prevedibili. Conoscere il meccanismo dietro ogni modello ti dice cosa è deterministicamente correggibile rispetto a cosa necessita di conferma dell'utente.
- Errori di digitazione di prossimità a livello di dominio (gmial, yhoo, hotnail). Questi seguono l'adiacenza della tastiera QWERTY — "i" e "a" si trovano uno accanto all'altro sulla fila principale, il dito indice scivola, il modulo accetta il risultato. ZeroBounce identifica questi come la singola più grande categoria di errore di digitazione nel suo dataset di 4 miliardi di indirizzi. Sono anche i più recuperabili: la distanza di Levenshtein dal dominio corretto è 1, il matching fuzzy rispetto a una breve lista di provider principali li cattura con alta precisione.
- Confusione TLD (.co vs .com, .net vs .com, .om vs .com). Guidata da tastiere mobili dove ".com" è un singolo tasto scorciatoia che può essere mancato, e da utenti in mercati con TLD con codice paese attivo (.co.uk, .com.au) che scrivono con memoria muscolare in una combinazione sbagliata. Particolarmente dannoso perché ".co" è di per sé un TLD valido assegnato alla Colombia. I controlli di esistenza del dominio passano cleanly. La cassetta postale molto probabilmente non esiste.
- Scambi di sottodominio e provider (outlook.com ↔ live.com, icloud ↔ icould, msn ↔ mns). Gli utenti ricordano male quale dominio Microsoft o Apple-era usa il loro account, specialmente dopo le migrazioni. Prevalenza più alta nei dati demografici di utenti più anziani dove l'iscrizione originale è avvenuta su un provider legacy. Il matching fuzzy rispetto a un registro di domini con errore di digitazione li cattura; regex no.
- Caratteri raddoppiati o omessi (aaccount, coom, gmaill, hotmai). Artefatti dell'autofill del touchscreen. La ricerca su text-entry di Azenkot e Zhai documenta sistematicamente tassi di errore a livello di carattere più elevati su touchscreen rispetto a tastiere hardware, particolarmente per stringhe che gli utenti non leggono visivamente prima di inviare. I campi email sono ad alto rischio perché sono lunghi, non-dizionario e visivamente densi.
- Override dell'autocorrezione mobile. Il testo predittivo "corregge" silenziosamente frammenti di email validi in parole comuni del dizionario ("gmail" → "gail," "outlook" → "outlooks"). La correzione è strutturale piuttosto che investigativa: i campi di input dovrebbero dichiarare
type="email"eautocomplete="email"per disabilitare l'autocorrezione a livello di OS. La guida al design del modulo della Nielsen Norman Group tratta questo come pratica di base per qualsiasi campo ad alto rischio di errore. - Slittamenti di spazi bianchi e punteggiatura (spazio finale, virgola-per-punto, doppio @). Spesso invisibili per l'utente perché il campo del modulo taglia visivamente il display, nascondendo il problema fino a quando SMTP rifiuta l'indirizzo. La logica strip-and-normalize al momento dell'acquisizione elimina il sottoinsieme recuperabile; il resto ha bisogno di convalida esplicita rispetto alla grammatica dell'indirizzo.
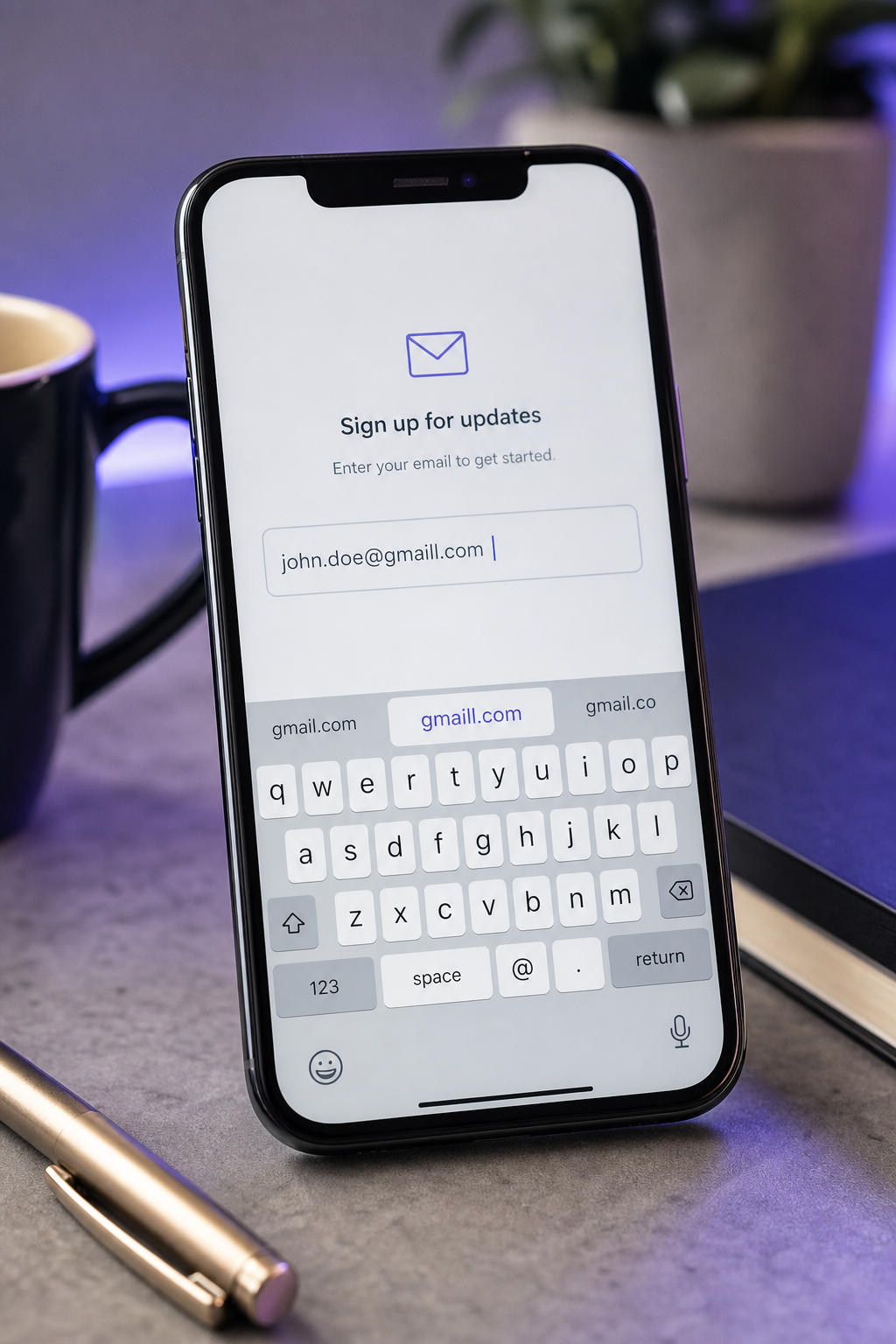
Di questi sei modelli, tre sono deterministicamente correggibili dalla stringa dell'indirizzo da sola (prossimità, TLD, caratteri raddoppiati), due richiedono la conferma dell'utente perché sono ambigui (scambi di sottodomini, override dell'autocorrezione), e uno è anticipato a livello di input prima che qualsiasi convalida venga eseguita (spazi bianchi). La mappa di correzione è importante perché imposta il contratto UX: quali modelli meritano una normalizzazione silenziosamente, quali meritano un prompt "Intendevi?", e quali meritano il blocco con un messaggio di errore.
Metodi di rilevamento confrontati — Cosa cattura effettivamente gli errori di digitazione al momento dell'acquisizione
La maggior parte dei team ha già qualcosa che convalida il loro campo email. La domanda è se quello che hanno cattura effettivamente la categoria di errore di digitazione rispetto alla categoria di sintassi. I cinque metodi sottostanti coprono lo spazio di opzioni realistico.
| Metodo | Cattura errori di digitazione | Tempo reale | Attrito aggiunto | Impatto sulla lista |
|---|---|---|---|---|
| Controllo di sintassi Regex / RFC | No | Sì | Nessuno | Nessuno |
| Conferma doppio opt-in | Dopo rimbalzo | No (asincrono) | Alto | 20–40% riduzione |
| Client-side fuzzy match | Parziale | Sì | Basso | Minimo |
| Controllo record MX del dominio | No | Sì | Nessuno | Basso |
| API di verifica in tempo reale | Sì | Sì (sub-500ms) | Minimo | Minimo |
Figura di riduzione doppio opt-in: Studio GetResponse single-vs-double opt-in. Latenza API in tempo reale: Documentazione API NeverBounce. Architettura di convalida a tre livelli (sintassi → MX → cassetta postale): Documentazione API ZeroBounce.
Regex è necessario ma insufficiente. Applica RFC 5321 e 5322 cleanly, scherma stringhe ovvie malformate e viene eseguito in zero tempo sul client. Ogni indirizzo con errore di digitazione discusso prima passa regex senza esitazioni. Tratta regex come il tuo primo filtro, mai come il tuo unico.
Doppio opt-in è la "soluzione" più popolare e la più costosa. Lo studio di GetResponse ha rilevato che gli elenchi doppio opt-in erano 20–40% più piccoli rispetto agli elenchi single opt-in — e gli utenti con errore di digitazione sono matematicamente garantiti di essere nel 20–40% mancante perché non possono ricevere l'email di conferma per definizione. Il meccanismo è a rovescio: le email di conferma diagnosticano il problema dell'errore di digitazione solo dopo che l'utente è già perso. Scopri l'errore di digitazione quando il messaggio di conferma stesso rimbalza duramente, momento in cui l'utente ha chiuso la scheda. Doppio opt-in ha ancora valore per il filtering di autorizzazione e impegno. Non è, in alcun senso significativo, uno strato di rilevamento dell'errore di digitazione.

Il matching fuzzy lato client ("Intendevi gmail.com?") è una buona UX, fragile come infrastruttura. Richiede di mantenere un dizionario di domini con errore di digitazione, gestire domini internazionalizzati e evitare la modalità di fallimento documentata da Baymard Institute in cui i TLD con codice paese legittimi o aziendali vengono contrassegnati come errori di digitazione. Il dizionario invecchia. Emergono nuovi modelli di errore di digitazione. Utile come livello UI in cima a una vera chiamata di verifica. Non è un sostituto per una.
I controlli del record MX escludono i domini non inesistenti ma perdono i casi di errore di digitazione di vero dominio. "gmial.com" è un dominio registrato, risolvente MX — è esattamente il motivo per cui è una trappola di errore di digitazione di lunga durata. Lo squatter vuole il traffico. I controlli MX catturano domini fabbricati; non catturano la categoria di errore di digitazione di cui parla questo articolo. Il controllo è poco costoso e vale la pena eseguirlo, ma non confondere il superarlo con l'essere un vero indirizzo.
Le API di verifica in tempo reale combinano tutti e quattro i livelli. L'architettura standard documentata da ZeroBounce e NeverBounce esegue sintassi → MX → probe a livello di cassetta postale → flag di dominio con errore di digitazione → flag di dominio temporaneo in una singola chiamata sub-500ms. L'output non è un pass/fail binario; è un verdetto classificato su cui il flusso di registrazione può ramificarsi diversamente per categoria. Una convalida dell'indirizzo email in tempo reale ritorna questi segnali come codici di risultato separati, il che è quello che ti permette di suggerire per errori di digitazione, bloccare per temporanei e rifiutare per non validi senza scrivere cinque validatori indipendenti.
La latenza non è un'obiezione. I tempi di risposta pubblicati di NeverBounce di 100–500ms sono al di sotto della soglia percettiva per il lag dell'UI, specialmente quando la chiamata si attiva su campo blur piuttosto che su submit. Gli utenti hanno già spostato la loro attenzione al campo successivo; il suggerimento appare quando guardano di nuovo.
Un flusso di registrazione resistente agli errori di digitazione in sette decisioni
L'architettura qui sotto è tattica, non teorica. Ogni elemento è una decisione che il team fa una volta e codifica nel percorso del codice di registrazione. Il ragionamento importa più della sintassi specifica — adatta al tuo stack.
- Convalida su blur, non solo su submit. Esegui la chiamata di verifica quando il campo email perde il focus in modo che il prompt di suggerimento appaia prima che l'utente si sia mentalmente impegnato nel campo successivo. La ricerca su moduli della Nielsen Norman Group mostra che la convalida inline supera la convalida al momento dell'invio per il recupero degli errori perché l'utente è ancora orientato al campo che ha appena lasciato. Gli errori al momento dell'invio richiedono un riorientamento e si sentono come una punizione.
- Usa una risposta API classificata dal verdetto, non un booleano. La risposta dovrebbe separare i flag di errore di digitazione, temporaneo, account di ruolo e cassetta postale non valida in modo che ognuno possa attivare un'interfaccia utente diversa. Le risposte booleane "is_valid" ti forzano a scegliere un trattamento per cinque problemi diversi, il che è come i team finiscono per bloccare gli utenti recuperabili. Le API dei vendor strutturano le risposte in questo modo per un motivo.
- Suggerisci, non auto-correggi. Per i flag di errore di digitazione, renderizza "Intendevi john@gmail.com?" come accettazione con un clic. L'auto-correzione silenziosamente viola la fiducia dell'utente — la ricerca su moduli di e-commerce di Baymard mostra che gli utenti abbandonano quando catturano un campo che cambia sotto di loro — e si interrompe per i casi limite legittimi come i domini aziendali che sembrano errori di digitazione ma non lo sono.
- Blocca il temporaneo separatamente dall'errore di digitazione. Un segnale di temporaneo merita un blocco duro o un downgrade a un account di livello guest con funzionalità limitate. Un segnale di errore di digitazione merita un suggerimento morbido con una correzione con un clic. Trattare entrambi allo stesso modo penalizza gli utenti recuperabili mentre proteggi insufficientemente contro l'abuso di prova. Il costo della ramificazione è un condizionale aggiuntivo.
- Disabilita l'autocorrezione a livello di input. Usa
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">. Questo anticipa il modello di override dell'autocorrezione prima che qualsiasi convalida venga eseguita. È un cambio di cinque attributi che elimina una intera classe di errore di digitazione. - Imposta soglie di rimbalzo duro e instrumentali. Sia M3AAWG che Mailchimp consigliano che i rimbalzi duri aggregati rimangano al di sotto dell'1% per campagna, con il 2% che è la zona di pericolo di deliverability. Allerta su tassi di rimbalzo coorte di iscrizione sopra l'1.5% — non solo sui tassi a livello di campagna. Il rimbalzo a livello di coorte è un indicatore iniziale che la tua convalida lato acquisizione sta fallendo per una fonte specifica, che i tassi a livello di campagna diluiranno.
- Registra modelli di errore di digitazione e rialimenta. Traccia quali domini i tuoi utenti più frequentemente scrivono male. Se il tuo pubblico produce un modello ricorrente "yaho.com" o ".cm", ora sai dove indurire la logica di suggerimento. Questo chiude il ciclo tra il rilevamento lato acquisizione e l'insight di igiene della lista in corso — e ti permette di misurare il delta effettivo da ogni cambio di convalida piuttosto che indovinare.

Il flusso nel suo insieme richiede un'integrazione API e una manciata di decisioni UI. Il payoff composto è che ogni sistema a valle — onboarding, fatturazione, supporto, marketing — opera su indirizzi che hanno già superato il filtro di errore di digitazione, temporaneo e non valido al confine. Smetti di diagnosticare i problemi di qualità della lista nei dashboard e inizia a prevenirli al modulo.
Quello che i professionisti chiedono effettivamente sui errori di digitazione email
- Una email di conferma non sta già catturando gli errori di digitazione? No — li diagnostica, non li cattura. Il confronto single-vs-double opt-in di GetResponse ha rilevato che il 20–40% degli utenti non conferma mai, e gli utenti con errore di digitazione sono matematicamente garantiti di essere nel gruppo mancante perché non possono ricevere la conferma per definizione. Scopri l'errore di digitazione quando il messaggio di conferma stesso rimbalza duramente, momento in cui l'utente ha chiuso la scheda e ha continuato. La convalida dell'indirizzo email in tempo reale lato acquisizione fa emergere l'errore di digitazione mentre l'utente è ancora sul modulo e può correggerlo con un clic. Le email di conferma rimangono preziose per il filtering di autorizzazione e impegno — provano che l'utente voleva effettivamente ricevere la tua posta. Non sono, meccanicamente, un sostituto per il rilevamento dell'errore di digitazione al momento dell'acquisizione. I due livelli fanno lavori diversi e dovrebbero coesistere.
- Se auto-correggo "gmial" a "gmail," sto saltando l'intento dell'utente? Stai correggendo un errore di input meccanico, non una scelta intenzionale — ma solo se confermi con l'utente. La ricerca su moduli di e-commerce della Baymard Institute mostra che le correzioni silenziose danneggiano la fiducia e interrompono i casi limite, in particolare i domini aziendali e i TLD regionali che sembrano errori di digitazione ma non lo sono (.co Colombia, .om Oman). Il modello difendibile è un suggerimento con un clic: "Intendevi john@gmail.com? [Sì, usa questo] [No, tieni il mio]." Questo preserva l'agenzia dell'utente mentre rende la correzione senza attrito. L'utente mantiene la decisione finale, l'indirizzo con errore di digitazione viene recuperato nel 95%+ dei casi in cui il suggerimento è corretto, e il raro caso legittimo edge ha un percorso di override pulito. Le riscritture silenziose si ottimizzano per la metrica sbagliata e producono un'esperienza peggiore per la coda lunga.
- Qual è la differenza tra un indirizzo con errore di digitazione e un indirizzo temporaneo — e perché importa? Un errore di digitazione è un utente legittimo con un errore meccanico; un temporaneo è un utente che attivamente evita una relazione. I segnali si sovrappongono a valle — entrambi producono rimbalzi, entrambi riducono la qualità della lista, entrambi danneggiano la deliverability — ma la risposta al momento dell'acquisizione dovrebbe differire. Gli errori di digitazione ricevono un prompt di suggerimento perché l'utente vuole entrare. I temporanei vengono bloccati o degradati perché l'utente sta rinunciando mentre sembra rinunciare. Un'API in tempo reale che li contrassegna separatamente ti permette di instradare ciascuno appropriatamente senza scrivere due validatori paralleli. Trattarli in modo identico o sovra-blocca gli utenti recuperabili (se rifiuti duramente gli errori di digitazione insieme ai temporanei) o proteggi insufficientemente contro l'abuso di prova (se solo morbidamente avverti i temporanei insieme agli errori di digitazione). Un checker dedicato per indirizzi email temporanei gestisce lo strato di rilevamento specifico al temporaneo; uno strato di suggerimento dell'errore di digitazione si posiziona in cima ad esso.
- Quante delle mie iscrizioni hanno effettivamente errori di digitazione in questo momento? I dati del settore convergono su 0.5–2% per tipi di pubblico B2B desktop-heavy e 2–3%+ per app consumer mobile-heavy, con il dataset di 4 miliardi di indirizzi di ZeroBounce e la ricerca su domini con errore di digitazione di Kickbox come le due fonti più citate. Per misurare la tua linea di base invece di indovinare: estrai i 90 giorni ultimi di iscrizioni, incrocia con il log di rimbalzo duro del tuo ESP, e isola i rimbalzi dove il dominio è a una distanza di Levenshtein da un provider principale (gmail, yahoo, hotmail, outlook, icloud, aol). Quel sottoinsieme è il tuo tasso di errore di digitazione attuale. Esegui la stessa query di nuovo 30 giorni dopo la distribuzione della convalida in tempo reale per misurare il delta cleanly. I numeri prima/dopo sono gli unici che contano per giustificare l'integrazione internamente.
- Posso costruire il rilevamento dell'errore di digitazione da solo senza un'API? Parzialmente. Uno script di matching fuzzy lato client rispetto a un elenco hardcoded di domini con errore di digitazione comune (gmial.com, yaho.com, hotnail.com, outlok.com, icould.com) cattura il top 60–70% dei casi a basso costo — distanza di Levenshtein ≤ 2 rispetto a un elenco di 20 provider principali copre una quota sorprendente del volume. I casi rimanenti richiedono infrastruttura: gestione della confusione TLD, rilevamento dello scambio di sottodomini, probe di non esistenza a livello di cassetta postale e un registro di domini con errore di digitazione continuamente aggiornato mentre emergono nuovi modelli. La soglia di build-vs-buy è solitamente se il tuo team vuole possedere la manutenzione del dizionario, l'infrastruttura di controllo MX e i probe SMTP a livello di cassetta postale in perpetuo. Per la maggior parte dei team, il percorso API è più economico dell'overhead di manutenzione, e il guadagno di copertura marginale sui modelli di coda lunga è dove vive il ricavo effettivo — non nel top 60% che qualsiasi script decente gestisce il primo giorno.