
Formularz rejestracji SaaS przechwytuje 500 nowych użytkowników we wtorek. Sekwencja onboardingu uruchamia się w środę rano. Do czwartku 7 wiadomości e-mail zwróciło się – nie z fałszywych adresów ani wiadomości jednorazowych, ale z „gmial.com", „yaho.com", „hotmial.com". Ci 7 użytkowników pisali szybko na urządzeniu mobilnym, kliknęli wyślij i poszli dalej. Nigdy nie zobaczą wiadomości e-mail aktywacyjnej. Niektórzy wrócą, winią produkt i zrezygnują. Reszta znika.
Każde błędne wpisanie e-maila w Twojej lejce konwersji należy do prawdziwej osoby, która chciała się zalogować. To nie jest oszustwo. To nie jest ruch botów. To jest cichy 1–3% każdej listy, który, według analizy ZeroBounce ponad 4 miliardów adresów, pojawia się jako domeny z literówkami – adresy, które przechodzą każdą kontrolę regex, wyglądają idealnie ważnie i po cichu łamią Twoją lejce, zanim dotrze pierwsza wiadomość e-mail onboardingu.

Spis treści
- Dlaczego literówka w e-mailu to inny problem niż fałszywy lub jednorazowy adres
- Rzeczywisty koszt literówek e-mail w pięciu modelach biznesowych
- Sześć wzorców literówek odpowiadających za większość złych adresów
- Porównanie metod wykrywania – co faktycznie łapie literówki podczas przechwytywania
- Przepływ rejestracji odporny na literówki w siedmiu decyzjach
- Co praktykownicy faktycznie pytają o literówki w e-mailach
Dlaczego literówka w e-mailu to inny problem niż fałszywy lub jednorazowy adres
Zacznij od taksonomii, ponieważ od niej zależy reszta artykułu. W każdym formularzu rejestracji pojawiają się trzy tryby awarii i wyglądają podobnie w dziennikach zwrotów, ale wymagają zupełnie innych odpowiedzi.
Adresy z literówkami to legalni użytkownicy z błędami wprowadzania mechanicznego: gmial.com, yaho.com, hotnail.com, outlok.com. Osoba chce tego e-maila. Oczekuje linku aktywacyjnego. Pisała szybko, pomyliła się o jeden znak, a formularz to zaakceptował. Każdy wskaźnik w Twojej lejce będzie traktować ich jako użytkowników zaangażowanych-a-następnie-zniknęłych, podczas gdy są to faktycznie użytkownicy niedostępni-od-początku.
Adresy jednorazowe są legalne w formacie, ale celowe w unikaniu: mailinator.com, tempmail.io, guerrillamail.com. Użytkownik aktywnie rezygnuje z relacji, jednocześnie udając, że się włącza. Chce wersji próbnej, zamkniętej zawartości, kodu rabatowego – nie wiadomości z cyklu życia. Dedykowany narzędzie do sprawdzania adresów jednorazowych zajmuje się tą kategorią, ponieważ logika wykrywania jest fundamentalnie wyszukiwaniem reputacji domeny, a nie obliczaniem bliskości.
Nieprawidłowe lub fałszywe adresy to ciągi śmieci, wymyślone domeny lub zgłoszenia botów: asdf@asdf.asdf, test@test.test. Brak intencji człowieka, brak odzyskiwalnego sygnału. Odrzuć i idź dalej.
Wymagają one innego traktowania na granicy rejestracji. Adres jednorazowy powinien być zablokowany lub obniżony do poziomu gościa. Literówka powinna być oznaczona monitem korekcji jednym kliknięciem. Adres fałszywy powinien być odrzucony z ogólnym błędem. Traktowanie ich jako jednej kategorii „złego e-maila" daje jeden z dwóch trybów awarii: albo dodajesz tarcie do odzyskiwalnych użytkowników, blokując ich w twardym trybie, albo akceptujesz wszystko i pochłaniasz szkodę od odbicia w dalszym ciągu. Oba są drogie.
Powód, dla którego walidacja regex nie może złapać literówek, jest strukturalny, a nie specyficzny dla implementacji. RFC 5321 i RFC 5322 definiują składnię adresu e-mail – dozwolone znaki, reguły cytowania, format domeny, limity długości. Ciąg „john@gmial.com" jest w pełni zgodny z RFC. Skrzynka pocztowa nie istnieje; domena jest zarejestrowana przez paserę literówek; użytkownik nigdy nie otrzyma ani jednego bajtu z Twoich serwerów. Ale ciąg jest ważny. Regex operuje na znakach, a nie na rozdzielczości DNS lub bliskości domeny. Jest to kategoria ograniczenia dopasowania wzorca, a nie coś, co można naprawić lepszym wzorem.
Adres z literówką jest w pełni zgodny z RFC, syntaktycznie idealny i strukturalnie nie do odróżnienia od prawdziwego – co jest dokładnie powodem, dla którego Twoja warstwa walidacji go przepuszcza.
Ukryta wielkość jest większa niż większość zespołów szacuje. Zestaw danych 4-miliardowych adresów ZeroBounce umieszcza domeny z literówkami w zakresie 1–3% typowych przechwytów formularzy internetowych. Badania domeny literówek Kickbox zauważają, że odbiorcy mobilni skłaniają się ku górnej granicy zakresu, ponieważ wprowadzanie za pośrednictwem ekranu dotykowego powoduje wyższe wskaźniki błędów na poziomie znaków niż klawiatury fizyczne. W przypadku SaaS wykonującego 10 000 rejestracji miesięcznie przy wskaźniku literówek na poziomie 1,5%, to 150 użytkowników co miesiąc, którzy sami się zdyskwalifikowali z każdej wiadomości e-mail dotyczącej cyklu życia, którą wysyłasz – aktywacja, edukacja funkcji, przypomnienia rozliczeń, powrót.
Te 150 użytkowników przepływa przez trzy kanały kosztów dalszych jednocześnie. Sekwencje onboardingu wpadają w pustotę, ciągnąc konwersję z wersji próbnej do płatnej. Poczta transakcyjna – resetowanie hasła, rachunki, kody dwuskładnikowe – nigdy nie dociera, generując zgłoszenia wsparcia w wysokości 5–15 USD każde. Kampanie marketingowe gromadzą twardy zwrot, który osłabia Twoją reputację nadawcy w całej domenie, nie tylko dla adresów z literówkami. Matryca kosztów w następnej sekcji określa ilościowo każdy kanał dla pięciu powszechnych modeli biznesowych.
Rzeczywisty koszt literówek e-mail w pięciu modelach biznesowych
Taki sam wskaźnik literówek na poziomie 1–3% powoduje dramatycznie różne szkody w dolarach w zależności od tego, co e-mail rzeczywiście robi w Twojej firmie. Literówka w lead B2B i literówka w koszyku e-commerce zawodzą na różne sposoby, w różnych osiach czasu, w stosunku do różnych linii bazowych przychodów.
| Model biznesowy | Utracona podstawowa funkcja e-maila | Wpływ wskaźnika literówek | Efekt kumulacyjny |
|---|---|---|---|
| Bezpłatna wersja próbna SaaS | Aktywacja + sekwencja onboardingu | 1–2% nigdy nie zaczyna wersji próbnej | 15–25% wzrostu onboardingu utracone |
| Kasa e-commerce | Potwierdzenie zamówienia + wysyłka | 1–3% wyzwala zgłoszenia pomocy | 5–15 USD za „gdzie jest moje zamówienie" |
| Biuletyn / zawartość | Powitalny + bieżące kampanie | 1–3% nigdy nie potwierdzi zaangażowania | Zwrot zbliża się do strefy niebezpiecznej 2% |
| Generowanie leadów B2B | Pielęgnacja leadów + przekazanie sprzedaży | 0,5–1,5% (duży pulpit) | Utracony MQL = całkowity koszt akwizycji zmarnowany |
| Aplikacja konsumencka skoncentrowana na urządzeniach mobilnych | Weryfikacja konta + ponowne zaangażowanie | 2–3%+ (pochylenie mobilne) | Pogłębia niską retencję mobilną |
Źródła wskaźnika literówek: analiza ZeroBounce 4-miliardowych adresów i badania domeny literówek Kickbox. Dane wzrostu onboardingu z Raportu metryk SaaS Totango 2023. Progi zwrotów z benchmarkami dostarczalności Mailchimp i Best Common Practices nadawcy M3AAWG. Wskaźniki błędów mobilnych z badań wprowadzania tekstu MobileHCI Azenkota i Zhai.
SaaS cierpi na najwyższy wpływ dolara na literówkę, ponieważ koszt narasta w całym cyklu życia klienta. Przejdź przez matematykę. Benchmarki Totango plasują wzrost strukturalnej sekwencji e-mail onboardingu na poziomie 15–25% w stosunku do braku sekwencji. Użytkownik z literówką odbiera zero e-maili onboardingu i powraca do konwersji bazowej. W planie za 50 USD/miesiąc ze średnim okresem ważności 12 miesięcy, delta konwersji o 20 punktów dla każdego utraconego użytkownika reprezentuje około 120 USD oczekiwanego przychodu na przechwycenie z literówką. Przy 10 000 rejestracji miesięcznie i wskaźniku literówek na poziomie 1,5%, to 150 użytkowników × 120 USD = około 18 000 USD miesięcznie w oczekiwanym przychodzeniu w ciszy utraconego – zanim uwzględnisz efekty polecenia, rozszerzenia lub pozycjonowania słowem w usta.
Każdy punkt procentowy niewykrytych literówek w Twojej formularzu rejestracji to punkt procentowy Twojej inwestycji w onboarding, który wchodzi w pustkę.
E-commerce płaci obciążeniem wsparcia, a nie tylko utraconym mailem. Dane benchmarku serwisu klienta Zendesk plasują problemy z uwierzytelnianiem i „nie otrzymałem mojego e-maila" wśród kategorii o najwyższym priorytecie przychodzących biletów, często stanowiąc 15–30% całkowitej objętości. Znaczna część wynika z przechwytywania z literówką, a nie z niepowodzenia dostarczalności po stronie nadawcy. Klient wpisał gmial.com, potwierdzenie zamówienia zwróciło się, klient zakłada, że zamówienie nie powiodło się, a bilet trafia do kolejki w wysokości 5–15 USD do rozwiązania ręcznie.
Nadawcy biuletynów stają wobec kaskad reputacji. Gdy 1–3% nowych rejestracji zwraca się twardo, przyspieszasz do limitu zwrotów na kampanię, który Mailchimp sygnalizuje jako strefę niebezpieczną dostarczalności. Szkoda nie jest ograniczona do adresów z literówkami – dostawcy usług internetowych stosują filtrowanie do całej domeny wysyłającej po tym, jak wskaźniki zwrotów utrzymują się powyżej 2%. Jedna zła kohorta przechwytywania może stłumić legalne umieszczenie w skrzynce odbiorczej dla następnych trzech kampanii.
Raportowany zwrot z inwestycji e-mail DMA na poziomie 35–42 USD za 1 USD wydanego (DMA Marketer Email Tracker) wzmacnia obliczenie kosztów. Nawet małe procenty niedostarczonych e-maili mnożą się na tym wskaźniku dźwigni. Wskaźnik literówek na poziomie 1,5% to nie 1,5% utraty przychodów – to 1,5% Twojej inwestycji w wysyłanie, która produkuje zero wyniku, podczas gdy pozostałe 98,5% produkuje opublikowany zwrot. Asymetria to powód, dla którego literówki są szczególnie warte naprawy w stosunku do ich pozornego rozmiaru.
Sześć wzorców literówek odpowiadających za większość złych adresów
Literówki nie są losowe. Grupują się w garstce wzorców mechanicznych napędzanych układem klawiatury, zachowaniem automatycznej korekcji mobilnej i przewidywalnymi skrótami poznawczymi. Znanie mechanizmu za każdym wzorem mówi Ci, co jest deterministycznie poprawialny w stosunku do tego, co wymaga potwierdzenia użytkownika.
- Literówki bliskości na poziomie domeny (gmial, yhoo, hotnail). Te następują po sąsiedztwie klawiatury QWERTY – „i" i „a" siedzą obok siebie w górnym wierszu, palec wskazujący się ślizga, formularz akceptuje wynik. ZeroBounce identyfikuje to jako jedną z największych kategorii literówek w swoim zestawie danych 4-miliardowych adresów. Są również najbardziej możliwe do odzyskania: odległość Levenshteina do prawidłowej domeny wynosi 1, fuzzy matching w stosunku do krótkiej listy głównych dostawców łapie je z wysoką precyzją.
- Pomyłka TLD (.co vs .com, .net vs .com, .om vs .com). Napędzane klawiaturami mobilnymi, gdzie „.com" to jeden klawisz skrótu, który można pominąć, oraz przez użytkowników na rynkach z aktywnymi TLD kodami krajów (.co.uk, .com.au), którzy poprzez pamięć mięśniową wpadają w złą kombinację. Szczególnie szkodliwe, ponieważ „.co" jest samo w sobie ważnym TLD przypisanym Kolumbii. Kontrole istnienia domeny przechodzą czyszczę. Skrzynka pocztowa prawie na pewno nie istnieje.
- Zamiany poddomeny i dostawcy (outlook.com ↔ live.com, icloud ↔ icould, msn ↔ mns). Użytkownicy źle pamiętają, która domena Microsoft lub Apple-era ich konta używa, szczególnie po migracjach. Wyższa prevalencja w starszych demograficznych grupach użytkowników, gdzie oryginalna rejestracja miała miejsce na starszym dostawcy. Fuzzy matching w stosunku do rejestru domeny literówek je łapie; regex nie.
- Podwojone lub pominięte znaki (aaccount, coom, gmaill, hotmai). Artefakty automatycznego wypełniania ekranu dotykowego. Badania wprowadzania tekstu Azenkota i Zhai dokumentują systematycznie wyższe wskaźniki błędów na poziomie znaków na ekranach dotykowych niż na klawiaturach sprzętowych, szczególnie dla ciągów, które użytkownicy nie czytają wizualnie przed przesłaniem. Pola e-mail są wysokiego ryzyka, ponieważ są długie, nie ze słownika i wizualnie gęste.
- Przesłonięcie automatycznej korekcji mobilnej. Tekst predykcyjny po cichu „poprawia" ważne fragmenty e-maila na popularne słowa ze słownika („gmail" → „gail", „outlook" → „outlooks"). Naprawa jest strukturalna, a nie detektywna: pola wejściowe powinny deklarować
type="email"iautocomplete="email", aby wyłączyć automatyczną korekcję na poziomie systemu operacyjnego. Wytyczne dotyczące projektowania formularzy Nielsen Norman Group traktują to jako praktykę podstawową dla każdego pola wysokiego ryzyka błędów. - Poślizgi spacji i interpunkcji (spacja końcowa, przecinek zamiast okresu, podwójny @). Często niewidoczne dla użytkownika, ponieważ pole formularza wizualnie przycina wyświetlanie, ukrywając problem do momentu, gdy SMTP odrzuca adres. Logika usuwania i normalizacji podczas przechwytywania eliminuje podzbiór odzyskiwalny; reszta wymaga wyraźnej walidacji w stosunku do gramatyki adresu.
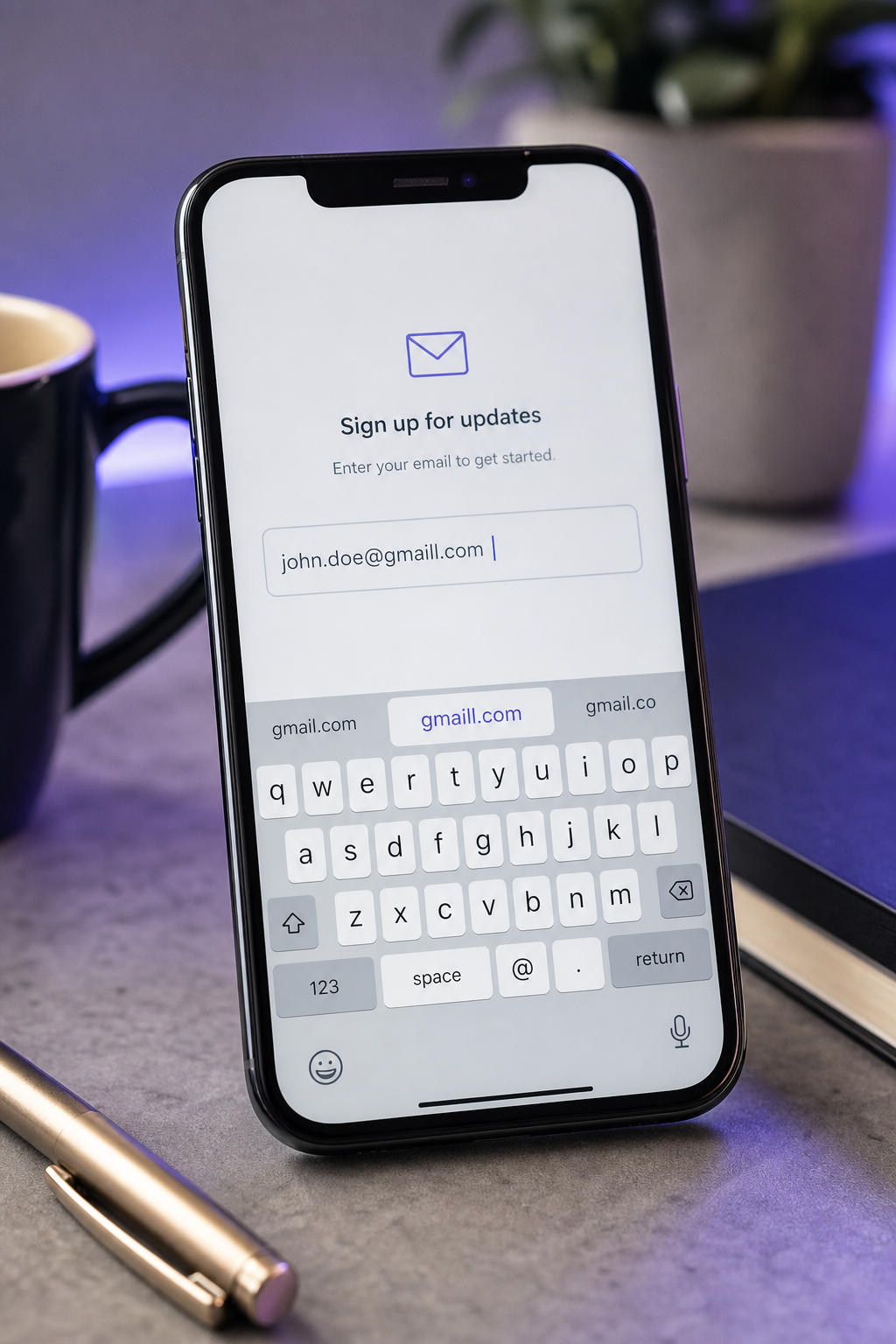
Z tych sześciu wzorców, trzy są deterministycznie poprawialne z ciągu adresu samego (bliskość, TLD, podwojone znaki), dwa wymagają potwierdzenia użytkownika, ponieważ są niejednoznaczne (zamiany poddomeny, przesłonięcia automatycznej korekcji), a jedno jest wstępnie uniemożliwiane na warstwie wejściowej, zanim jakakolwiek walidacja uruchomi (spacja). Mapa korygowania ma znaczenie, ponieważ ustawia kontrakt UX: które wzorce uzasadniają cichą normalizację, które uzasadniają monit „Czy chodziło Ci o?", a które uzasadniają blokowanie z komunikatem o błędzie.
Porównanie metod wykrywania – co faktycznie łapie literówki podczas przechwytywania
Większość zespołów już ma coś walidujące ich pole e-mail. Pytanie brzmi, czy to, co mają, faktycznie łapie kategorię literówek, w przeciwieństwie do kategorii składni. Pięć metod poniżej obejmuje realistyczne pole opcji.
| Metoda | Łapie literówki | Czas rzeczywisty | Dodane tarcie | Wpływ listy |
|---|---|---|---|---|
| Sprawdzenie składni Regex / RFC | Nie | Tak | Brak | Brak |
| Potwierdzenie podwójnej opcji | Po zwrocie | Nie (async) | Wysokie | 20–40% skurczenie |
| Fuzzy match po stronie klienta | Częściowo | Tak | Niskie | Minimalne |
| Kontrola rekordu MX domeny | Nie | Tak | Brak | Niskie |
| Interfejs API weryfikacji w czasie rzeczywistym | Tak | Tak (poniżej 500ms) | Minimalne | Minimalne |
Cyfra skurczenia podwójnej opcji: Badanie pojedynczej vs podwójnej opcji GetResponse. Opóźnienie interfejsu API w czasie rzeczywistym: Dokumentacja interfejsu API NeverBounce. Architektura walidacji trzywarstwowej (składnia → MX → skrzynka pocztowa): Dokumentacja interfejsu API ZeroBounce.
Regex jest konieczny, ale niewystarczający. Egzekwuje RFC 5321 i 5322 czyszczę, odfiltrowuje oczywiste źle sformułowane ciągi i działa w zerowym czasie na kliencie. Każdy adres z literówką omówiony wcześniej przechodzi regex bez oporów. Traktuj regex jako pierwszy filtr, nigdy jako jedyny.
Podwójna opcja to najpopularniejsze „rozwiązanie" i najdroższe. Badanie GetResponse wykazało, że listy z podwójną opcją były 20–40% mniejsze niż listy z pojedynczą opcją – i użytkownicy z literówkami są matematycznie gwarantowani, aby być w brakujące 20–40%, ponieważ nie mogą otrzymać wiadomości e-mail potwierdzającej z definicji. Mechanizm jest odwrotny: wiadomości e-mail potwierdzające diagnozują problem literówki tylko po tym, jak użytkownik już jest utracony. Odkrywasz literówkę, gdy sama wiadomość potwierdzająca zwraca się twardo, w takim punkcie użytkownik zamknął kartę i poszedł dalej. Podwójna opcja nadal ma wartość dla filtrowania uprawnień i zaangażowania. To nie jest, w żaden znaczący sens, warstwa wykrywania literówek.

Fuzzy matching po stronie klienta („Czy chodziło Ci o gmail.com?") to dobre UX, kruche jako infrastruktura. Wymaga utrzymywania słownika domeny literówek, obsługi domen międzynarodowych i unikania trybu awarii udokumentowanego przez Baymard Institute, w którym legalne domeny kodów krajów lub korporacyjne TLD są oznaczane jako literówki. Słownik starzeje się. Pojawiają się nowe wzorce błędów. Przydatne jako warstwa interfejsu użytkownika na wierzchu rzeczywistego wezwania weryfikacyjnego. Nie zamiennik dla jednego.
Kontrole rekordu MX reguły odrzucają nieistniejące domeny, ale miss typo-of-real-domain cases. „gmial.com" to zarejestrowana, MX-rozwiązywana domena – to dokładnie dlatego, że to długotrwała pułapka literówek. Paserz chce ruchu. Kontrole MX łapią wymyślone domeny; nie łapią kategorii literówek, o której mówi ten artykuł. Kontrola jest tania i warta uruchomienia, ale nie mylić jej przejścia z rzeczywistą adresem.
Interfejsy API weryfikacji w czasie rzeczywistym łączą wszystkie cztery warstwy. Standardowa architektura udokumentowana przez ZeroBounce i NeverBounce uruchamia składnię → MX → sondę poziomu skrzynki pocztowej → flaga domeny literówek → flaga domeny jednorazowej w pojedynczym wezwaniu poniżej 500ms. Wyjście to nie binarny pass/fail; to zaklasyfikowany werdykt, na którym przepływ rejestracji może rozgałęziać się inaczej na kategorię. Rzeczywiste wezwanie walidacji adresu e-mail zwraca te sygnały jako oddzielne kody wyników, co pozwala Ci sugerować literówki, blokować jednorazowe i odrzucać niepoprawne bez pisania pięciu niezależnych walidatorów.
Opóźnienie nie jest zastrzeżeniem. Opublikowane czasy odpowiedzi NeverBounce na poziomie 100–500ms są poniżej progu percepcyjnego dla opóźnienia interfejsu użytkownika, szczególnie gdy wezwanie wychodzi na rozmycie pola, a nie na przesłanie. Użytkownicy już przenieśli swoją uwagę do następnego pola; sugestia pojawia się, gdy spojrzą wstecz.
Przepływ rejestracji odporny na literówki w siedmiu decyzjach
Poniższa architektura jest taktyczna, a nie teoretyczna. Każdy element to decyzja, którą zespół podejmuje raz i kodyfikuje w ścieżce kodu rejestracji. Logika ma większe znaczenie niż składnia określona – dostosuj do swojego stosu.
- Waliduj na rozmycie, a nie tylko na przesłanie. Uruchom wezwanie weryfikacji, gdy pole e-mail traci ostrość, aby monit sugestii pojawił się, zanim użytkownik psychicznie zobowiąże się do następnego pola. Badania formularzy Nielsen Norman Group pokazują, że walidacja wewnętrzna przewyższa walidację czasu przesłania w odzyskiwaniu błędów, ponieważ użytkownik jest nadal zorientowany na pole, które właśnie opuścił. Błędy w czasie przesłania wymagają re-orientacji i czują się jak kara.
- Użyj odpowiedzi API zaklasyfikowanej werdyktem, a nie logicznej wartości. Odpowiedź powinna oddzielić flagi literówki, jednorazowe, konto roli i niepoprawne-skrzynka-pocztowa, aby każda mogła wyzwolić inne interfejsy użytkownika. Odpowiedzi „is_valid" logiczne zmuszają Cię do wyboru jednego traktowania dla pięciu różnych problemów, co prowadzi do tego, że zespoły blokują odzyskiwalnych użytkowników. Interfejsy API dostawców strukturyzują odpowiedzi w ten sposób z powodu.
- Sugeruj, nie poprawiaj automatycznie. Dla flag literówek renderuj „Czy chodziło Ci o john@gmail.com?" jako akceptacja jednym kliknięciem. Cicha auto-korekta narusza zaufanie użytkownika – badania formularza e-commerce Baymard pokazują, że użytkownicy porzucają, gdy złapią pole zmieniające się pod nimi – i łamie to dla legicznych przypadków brzegowych, takich jak domeny korporacyjne, które wyglądają jak literówki, ale nie.
- Blokuj jednorazowy osobno od literówki. Sygnał jednorazowy uzasadnia twardą blokadę lub obniżenie do konta gościa z ograniczonymi funkcjami. Sygnał literówki uzasadnia mięką sugestię z jednym kliknięciem, aby naprawić. Traktowanie obu jednakowo karze odzyskiwalnych użytkowników, jednocześnie niedostatecznie chroniąc przed próbą złośliwą. Koszt rozgałęzienia to jeden dodatkowy warunek.
- Wyłącz automatyczną korekcję na warstwie wejściowej. Użyj
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">. To wstępnie uniemożliwia wzorzec przesłonięcia automatycznej korekcji, zanim jakakolwiek walidacja uruchomi. To zmiana pięciu atrybutów, która eliminuje całą klasę literówek. - Ustaw progi twardego odbicia i je instrumentuj. M3AAWG i Mailchimp zarówno doradzają, aby zagregowane twarde zwroty pozostawały poniżej 1% na kampanię, przy 2% będącej strefą niebezpieczną dostarczalności. Powiadom na wskaźnikach zwrotów kohorty rejestracji powyżej 1,5% – nie tylko wskaźnikach całej kampanii. Zwrot na poziomie kohorty jest wiodącym wskaźnikiem, że Twoja walidacja po stronie przechwytywania zawodzi dla określonego źródła, które wskaźniki całej kampanii będą rozcieńczać.
- Rejestruj wzorce literówek i przesyłaj je z powrotem. Śledź, które domeny Twoi użytkownicy najczęściej źle wpisują. Jeśli Twoja publiczność produkuje powtarzający się wzorzec „yaho.com" lub „.cm", wiesz teraz, gdzie utwardzić logikę sugestii. To zamyka pętlę między wykrywaniem czasu przechwytywania a bieżącym wglądem w higienę listy – i pozwala Ci zmierzyć rzeczywistą deltę każdej zmiany walidacji, zamiast zgadywać.

Przepływ jako całość zajmuje jedną integrację interfejsu API i garstką decyzji interfejsu użytkownika. Zwrot kumulacyjny jest taki, że każdy system podrzędny – onboarding, rozliczenia, wsparcie, marketing – działa na adresach, które już przeszły filtry literówek, jednorazowych i niepoprawnych na granicy. Przestajesz diagnozować problemy z jakością listy na pulpitach i zamiast tego zapobiega im na formularzu.
Co praktykownicy faktycznie pytają o literówki w e-mailach
- Czy wiadomość e-mail potwierdzająca nie łapie już literówek? Nie – diagnozuje je, nie łapie. Porównanie pojedynczej vs podwójnej opcji GetResponse wykazało, że 20–40% użytkowników nigdy nie potwierdza, a użytkownicy z literówkami są matematycznie gwarantowani, aby być w brakującej grupie, ponieważ nie mogą otrzymać potwierdzenia z definicji. Dowiadujemy się o literówce tylko wtedy, gdy sama wiadomość potwierdzająca zwraca się twardo, w takim punkcie użytkownik zamknął kartę i poszedł dalej. Rzeczywista walidacja adresu e-mail po stronie przechwytywania w czasie rzeczywistym wyświetla literówkę, podczas gdy użytkownik nadal jest na formularzu i może ją naprawić jednym kliknięciem. Wiadomości e-mail potwierdzające nadal mają wartość dla filtrowania uprawnień i zaangażowania – dowodzą, że użytkownik faktycznie chciał otrzymać Twoją pocztę. Mechanicznie nie są zamiennikiem dla wykrywania literówek podczas przechwytywania. Obie warstwy radzą sobie z różnymi zadaniami i powinny współistnieć.
- Jeśli automatycznie poprawię „gmial" na „gmail", czy przesłoniam intencję użytkownika? Poprawiasz błąd wprowadzania mechanicznego, a nie świadomą opcję – ale tylko jeśli potwierdzisz to użytkownikowi. Badania formularza e-commerce Baymard Institute pokazują, że cichy fixes zagrażają zaufaniu i łamią przypadki brzegowe, szczególnie domeny korporacyjne i regionalne TLD, które wyglądają jak literówki, ale nie (.co Kolumbia, .om Oman). Wzorzec obronny to sugestia jednym kliknięciem: „Czy chodziło Ci o john@gmail.com? [Tak, użyj tego] [Nie, zachowaj mój]." To zachowuje sprawczość użytkownika przy jednoczesnym uproszczeniu korekcji. Użytkownik zachowuje ostateczną decyzję, adres z literówką zostaje odzyskany w 95%+ przypadków, gdy sugestia jest prawidłowa, a rzadki legiony przypadek brzegowy ma czystą ścieżkę przesłonięcia. Cichy zamiany optymalizują dla niepoprawnej metryki i wytwarzają gorsze doświadczenie dla długiego ogona.
- Jaka jest różnica między adresem z literówką a adresem jednorazowym – i dlaczego to ma znaczenie? Literówka to legalni użytkownik z błędem mechanicznym; jednorazowy to użytkownik aktywnie unikający relacji. Sygnały nakładają się dalej – oba produkują zwroty, oba zmniejszają jakość listy, oba szkodzą dostarczalności – ale odpowiedź podczas przechwytywania powinna się różnić. Literówki dostają monit sugestii, ponieważ użytkownik chce wejść. Jednorazowe dostają blokadę lub obniżenie, ponieważ użytkownik rezygnuje, podczas gdy udaje, że się włącza. Interfejs API w czasie rzeczywistym, który je flagi osobno, pozwala Ci kierować każdy odpowiednio bez pisania dwóch równoległych walidatorów. Traktowanie ich identycznie albo nadmiernie blokuje odzyskiwalnych użytkowników (jeśli twardo odrzucisz literówki razem z jednorazowymi) albo niedostatecznie chroni przed próbą (jeśli tylko miękko ostrzegasz jednorazowe razem z literówkami). Dedykowany narzędzie do sprawdzania adresów jednorazowych obsługuje warstwę wykrywania specyficzną dla jednorazowych; warstwa sugestii literówek siedzi na wierzchu.
- Ile moich rejestracji faktycznie ma literówki teraz? Dane branżowe zbiegają się na 0,5–2% dla publiczności B2B skoncentrowanej na komputerach stacjonarnych i 2–3%+ dla aplikacji konsumenckiej skoncentrowanej na urządzeniach mobilnych, przy czym zestaw danych 4-miliardowych adresów ZeroBounce i badania domeny literówek Kickbox są dwoma najczęściej przytaczanymi źródłami. Aby zmierzyć Twoją własną linię bazową zamiast zgadywać: wyciągnij ostatnie 90 dni rejestracji, krzyż-referencja w stosunku do dziennika twardego zwrotu Twojego ESP i wyizoluj zwroty, gdzie domena jest jednym znakiem Levenshteina od głównego dostawcy (gmail, yahoo, hotmail, outlook, icloud, aol). Ten podzbiór to Twój obecny wskaźnik literówek. Ponownie uruchom to samo zapytanie 30 dni po wdrożeniu walidacji w czasie rzeczywistym, aby zmierzyć deltę czyszczę. Numery przed/po to jedyne, które mają znaczenie do uzasadnienia integracji wewnętrznie.
- Czy mogę zbudować detektywne literówki sam bez interfejsu API? Częściowo. Skrypt fuzzy-matchingu po stronie klienta w stosunku do twardej kodowanej listy wspólnych domen literówek (gmial.com, yaho.com, hotnail.com, outlok.com, icould.com) łapie górne 60–70% przypadków przy niskich kosztach – odległość Levenshteina ≤ 2 w stosunku do listy 20 głównych dostawców obejmuje zaskakujący udział objętości. Pozostałe przypadki wymagają infrastruktury: obsługa zamieszania TLD, detektywne zamiany poddomeny, sondy poziomu skrzynki pocztowej, oraz ciągle aktualizowany rejestr domeny literówek, gdy pojawiają się nowe wzorce. Próg budowania vs kupna to zwykle to, czy Twój zespół chce posiadać konserwację słownika, infrastrukturę kontroli MX i sondy SMTP poziomu skrzynki pocztowej w wieczność. Dla większości zespołów ścieżka interfejsu API jest tańsza niż narzut konserwacji, a marginalny zysk pokrycia na wzorzec długiego ogona to gdzie rzeczywisty przychód żyje – nie w górnym 60%, które każdy przyzwoity skrypt obsługuje w dzień pierwszy.