
Форма регистрации SaaS привлекает 500 новых пользователей во вторник. Последовательность адаптации запускается в среду утром. К четвергу 7 писем получили жёсткий отскок — не с поддельных адресов или одноразовых, а с "gmial.com", "yaho.com", "hotmial.com". Эти 7 пользователей быстро печатали на мобильном телефоне, нажали отправить и ушли. Они никогда не увидят письмо активации. Некоторые вернутся, обвинят продукт и уйдут. Остальные исчезнут.
Каждая опечатка в email в вашей воронке привлечения принадлежит реальному человеку, который хотел присоединиться. Это не мошенничество. Это не поддельный трафик. Это тихие 1–3% каждого списка, которые, согласно анализу ZeroBounce более 4 миллиардов адресов, появляются как домены с опечатками — адреса, которые проходят все проверки regex, выглядят совершенно правильно и молча ломают вашу воронку до прихода первого письма адаптации.

Содержание
- Почему опечатка в email — это другая проблема, чем поддельный или одноразовый адрес
- Реальная стоимость опечаток в email в пяти бизнес-моделях
- Шесть паттернов опечаток, которые объясняют большинство неверных адресов
- Сравнение методов обнаружения — что действительно ловит опечатки при привлечении
- Устойчивый к опечаткам поток регистрации в семи решениях
- Что практики действительно спрашивают об опечатках в email
Почему опечатка в email — это другая проблема, чем поддельный или одноразовый адрес
Начните с таксономии, потому что от этого зависит весь остальной материал. В каждой форме регистрации видны три режима отказа, и они выглядят одинаково в журналах отскоков, требуя при этом совершенно разных ответов.
Адреса с опечатками — это законные пользователи с механическими ошибками ввода: gmial.com, yaho.com, hotnail.com, outlok.com. Человек хочет получить письмо. Он ожидает ссылку активации. Он быстро печатал, ошибся на один символ, и форма это приняла. Каждый метрик в вашей воронке будет рассматривать их как пользователей, которые были заинтересованы и исчезли, хотя на самом деле это пользователи, которые были недостижимы с самого начала.
Одноразовые адреса — это законные по формату, но намеренные в избегании: mailinator.com, tempmail.io, guerrillamail.com. Пользователь активно отказывается от отношений, выглядя при этом как одобрение. Он хочет пробный период, закрытый контент, код скидки — не сообщения о жизненном цикле. Специализированный инструмент проверки одноразовых email адресов справляется с этой категорией, потому что логика обнаружения в своей сути является проверкой репутации домена, а не расчётом близости.
Недействительные или поддельные адреса — это мусорные строки, вымышленные домены или ботовые отправки: asdf@asdf.asdf, test@test.test. Никакого человеческого намерения, никакого восстанавливаемого сигнала. Отклоните и двигайтесь дальше.
Эти категории требуют разного подхода на границе регистрации. Одноразовый адрес должен быть заблокирован или понижен до гостевого уровня. Опечатка должна быть отмечена подсказкой исправления одним щелчком. Поддельный адрес должен быть отклонён с общей ошибкой. Рассмотрение их как единой категории "плохого email" создаёт один из двух режимов отказа: либо вы добавляете трение к восстанавливаемым пользователям, жёстко их блокируя, либо вы принимаете всё и поглощаете урон отскока ниже по течению. Оба дорогостоящи.
Причина, по которой проверка regex не может ловить опечатки, структурна, а не специфична для реализации. RFC 5321 и RFC 5322 определяют синтаксис email адреса — допустимые символы, правила цитирования, формат домена, ограничения по длине. Строка "john@gmial.com" полностью соответствует RFC. Почтовый ящик не существует; домен зарегистрирован на охотника за опечатками; пользователь никогда не получит ни одного байта от ваших серверов. Но строка действительна. Regex работает с символами, а не с разрешением DNS или близостью домена. Это предел категории сопоставления шаблонов, а не то, что вы можете исправить с помощью лучшего шаблона.
Адрес с опечаткой полностью соответствует RFC, синтаксически совершенен и структурно неотличим от реального — что именно почему ваш слой валидации его пропускает.
Скрытый объём больше, чем оценивает большинство команд. Набор данных из 4 миллиардов адресов ZeroBounce помещает домены с опечатками в диапазон 1–3% типичных захватов веб-форм. Исследование typo-domain компании Kickbox отмечает, что мобильные аудитории смещают верхний край этого диапазона, потому что ввод на сенсорном экране производит более высокие показатели ошибок на уровне символов, чем физические клавиатуры. Для SaaS, делающей 10 000 регистраций в месяц при уровне опечаток 1.5%, это 150 пользователей каждый месяц, которые саморазквалифицировались из каждого письма жизненного цикла, который вы отправляете — активация, образование функций, напоминания о биллинге, возвратные кампании.
Эти 150 пользователей проходят через три канала затрат ниже по течению одновременно. Последовательности адаптации срабатывают в пустоту, снижая конверсию пробного периода в платное. Трансакционная почта — сброс пароля, квитанции, коды двухфакторной аутентификации — никогда не приходит, порождая тикеты поддержки по $5–15 каждый. Маркетинговые кампании накапливают жёсткие отскоки, которые эродируют вашу репутацию отправителя по всему домену, а не только для адресов с опечатками. Матрица затрат в следующем разделе количественно определяет каждый канал для пяти распространённых бизнес-моделей.
Реальная стоимость опечаток в email в пяти бизнес-моделях
Один и тот же уровень опечаток 1–3% производит кардинально различный финансовый урон в зависимости от того, что email действительно делает в вашем бизнесе. Опечатка B2B лида и опечатка при оформлении e-commerce отказывают по-разному, по разным временным шкалам, по сравнению с разными базами доходов.
| Бизнес-модель | Потеря первичной функции email | Влияние уровня опечаток | Кумулятивный эффект |
|---|---|---|---|
| SaaS пробный период | Активация + последовательность адаптации | 1–2% никогда не начинают пробный период | 15–25% подъёма адаптации потеряно |
| E-commerce оформление | Подтверждение заказа + доставка | 1–3% срабатывают тикеты поддержки | $5–15 за "где мой заказ" |
| Рассылка / контент | Добро пожаловать + текущие кампании | 1–3% никогда не подтверждают вовлечение | Отскок приближается к зоне опасности 2% |
| B2B генерация лидов | Воспитание лида + передача продажам | 0.5–1.5% (ориентированные на рабочий стол) | Потеря MQL = полностью потраченный CAC |
| Мобильное приложение, ориентированное на потребителя | Проверка учётной записи + повторное вовлечение | 2–3%+ (мобильный перекос) | Усугубляет низкую мобильную удержание |
Источники уровня опечаток: анализ 4 миллиардов адресов ZeroBounce и исследование typo-domain Kickbox. Показатели подъёма адаптации из отчёта о метриках SaaS Totango 2023. Пороги отскока из эталонов доставляемости Mailchimp и общих практик отправителей M3AAWG. Показатели ошибок мобильной связи из исследования ввода текста MobileHCI Азенкота и Чжая.
SaaS страдает от наивысшего влияния на доллар за опечатку, потому что затраты компенсируют весь жизненный цикл клиента. Рассчитаем. Эталоны Totango помещают подъём от структурированной последовательности email адаптации на 15–25% сверх отсутствия последовательности. Пользователь с опечаткой получает нулевых писем адаптации и возвращается к базовой конверсии. Для плана $50/месяц со средним сроком действия 12 месяцев дельта конверсии на 20 пунктов для каждого потеряного пользователя составляет примерно $120 ожидаемого дохода на регистрацию с опечаткой. При 10 000 регистраций в месяц и уровне опечаток 1.5%, это 150 пользователей × $120 = примерно $18 000 в месяц ожидаемого дохода, молча потеряно — до подсчёта рефералов, расширения или эффектов из уст в уста.
Каждый процентный пункт необнаруженных опечаток в вашей форме регистрации — это процентный пункт вашей инвестиции в адаптацию, которая срабатывает в пустоту.
E-commerce платит объёмом поддержки, а не только потерянной почтой. Данные эталона обслуживания клиентов Zendesk помещают проблемы аутентификации и "я не получил своё письмо" среди основных категорий входящих тикетов, часто составляя 15–30% от общего объёма. Значительная доля восходит к опечатке при привлечении, а не к отказу доставляемости на стороне отправителя. Клиент напечатал gmial.com, подтверждение заказа получило жёсткий отскок, клиент предполагает, что заказ не удался, и тикет встаёт в очередь по $5–15 для разрешения вручную.
Отправители рассылок сталкиваются с каскадами репутации. Когда 1–3% новых подписок получают жёсткий отскок, вы ускоряетесь к потолку отскока за кампанию, который Mailchimp отмечает как зону опасности доставляемости. Урон не изолирован только для адресов с опечатками — ISP применяют фильтрацию ко всему вашему домену отправки после того, как показатели отскока устойчиво превышают 2%. Одна плохая когорта привлечения может подавить законное размещение во входящих для следующих трёх кампаний.
Сообщённый DMA ROI email в $35–$42 за $1 потраченных (DMA Marketer Email Tracker) усиливает расчёт затрат. Даже небольшие процентные доли недоставленных писем умножают на это соотношение рычага. Уровень опечаток 1.5% не является потерей дохода 1.5% — это 1.5% ваших инвестиций в отправку, производящих нулевой выход, в то время как оставшиеся 98.5% производят опубликованный ROI. Асимметрия — вот что делает опечатки особенно стоящими исправления относительно их кажущегося размера.
Шесть паттернов опечаток, которые объясняют большинство неверных адресов
Опечатки не случайны. Они кластеризуются в несколько механических паттернов, управляемых раскладкой клавиатуры, поведением мобильного автозаполнения и предсказуемыми когнитивными ярлыками. Знание механизма, стоящего за каждым паттерном, говорит вам, что детерминированно исправляемо из строки адреса самой по себе, против что нуждается в подтверждении пользователя.
- Опечатки на уровне домена (gmial, yhoo, hotnail). Эти следуют соседству клавиатуры QWERTY — "i" и "a" сидят рядом в домашнем ряду, указательный палец скользит, форма принимает результат. ZeroBounce определяет эти как единую крупнейшую категорию опечаток в его наборе данных из 4 миллиардов адресов. Они также наиболее восстанавливаемы: расстояние Левенштейна к правильному домену составляет 1, нечёткое совпадение с коротким списком основных провайдеров ловит их с высокой точностью.
- Путаница TLD (.co vs .com, .net vs .com, .om vs .com). Управляется мобильными клавиатурами, где ".com" — это единая клавиша ярлыка, которую можно пропустить, и пользователями на рынках с активными домотоп-кодами (.co.uk, .com.au), которые мышечной памятью входят в неправильную комбинацию. Особенно разрушительна, потому что ".co" сам по себе действительный TLD, назначенный Колумбии. Проверки существования домена проходят чисто. Почтовый ящик почти определённо не существует.
- Подмена поддомена и провайдера (outlook.com ↔ live.com, icloud ↔ icould, msn ↔ mns). Пользователи неправильно помнят, какой Microsoft или Apple-эпохи домен использует их учётная запись, особенно после миграций. Более высокая распространённость в более старых демографических группах пользователей, где первоначальная регистрация произошла на устаревшем провайдере. Нечёткое совпадение с реестром typo-domain ловит эти; regex не.
- Удвоенные или опущенные символы (aaccount, coom, gmaill, hotmai). Артефакты автозаполнения сенсорного экрана. Исследование ввода текста Азенкота и Чжая документирует систематически более высокие показатели ошибок на уровне символов на сенсорных экранах, чем на аппаратных клавиатурах, особенно для строк, которые пользователи не проверяют визуально перед отправкой. Поля email находятся в группе высокого риска, потому что они длинные, не-словарные, и визуально плотные.
- Переопределения мобильного автозаполнения. Прогностический текст тихо "исправляет" действительные фрагменты email в общие слова словаря ("gmail" → "gail," "outlook" → "outlooks"). Исправление структурно, а не сыщицкое: поля ввода должны объявлять
type="email"иautocomplete="email", чтобы отключить автозаполнение на уровне ОС. Руководство по дизайну форм Nielsen Norman Group рассматривает это как основную практику для любого поля с высоким риском ошибки. - Проскальзывания пробела и пунктуации (пробел в конце, запятая-вместо-точки, удвоенный @). Часто невидимы пользователю, потому что поле формы визуально срезает дисплей, скрывая проблему до тех пор, пока SMTP не отклонит адрес. Логика strip-and-normalize при привлечении устраняет восстанавливаемое подмножество; остальное нужна явная валидация против грамматики адреса.
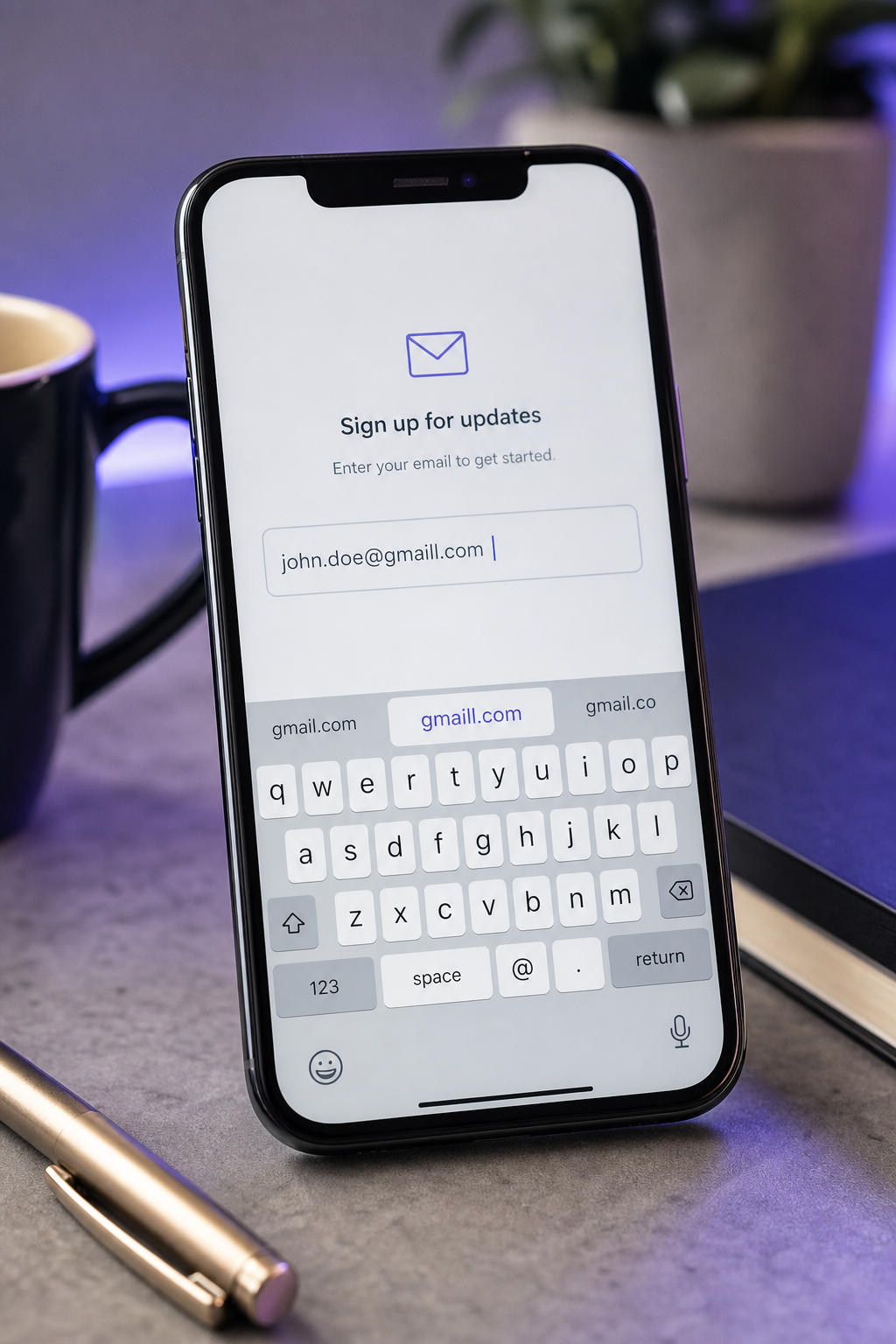
Из этих шести паттернов три детерминированно исправляемы из строки адреса самой по себе (близость, TLD, удвоенные символы), два требуют подтверждения пользователя, потому что они неоднозначны (подмена поддомена, переопределения автозаполнения), и один предотвращается на слое ввода до любой валидации (пробел). Карта восстановления важна, потому что она задаёт контракт UX: какие паттерны гарантируют молчаливую нормализацию, какие гарантируют подсказку "Вы имели в виду?", и какие гарантируют блокировку с сообщением об ошибке.
Сравнение методов обнаружения — что действительно ловит опечатки при привлечении
У большинства команд уже есть что-то, валидирующее их поле email. Вопрос в том, действительно ли то, что у них есть, ловит категорию опечатки в отличие от синтаксической категории. Пять методов ниже охватывают реалистичное пространство опций.
| Метод | Ловит опечатки | В реальном времени | Добавленное трение | Влияние на список |
|---|---|---|---|---|
| Regex / проверка синтаксиса RFC | Нет | Да | Нет | Нет |
| Подтверждение двойного согласия | После отскока | Нет (асинхронно) | Высокое | Сокращение на 20–40% |
| Нечёткое совпадение на стороне клиента | Частичное | Да | Низкое | Минимальное |
| Проверка MX записи домена | Нет | Да | Нет | Низкое |
| API верификации в реальном времени | Да | Да (меньше 500мс) | Минимальное | Минимальное |
Показатель сокращения двойного согласия: исследование GetResponse одиночного vs двойного согласия. Задержка API в реальном времени: документация API NeverBounce. Трёхслойная архитектура валидации (синтаксис → MX → почтовый ящик): документация API ZeroBounce.
Regex необходимо, но недостаточно. Он тщательно применяет RFC 5321 и 5322, экранирует явно неправильные строки и работает в нулевое время на клиенте. Каждый адрес с опечаткой, обсуждённый ранее, проходит regex без колебаний. Рассматривайте regex как ваш первый фильтр, никогда как ваш единственный.
Двойное согласие — наиболее популярное "решение" и наиболее дорогостоящее. Исследование GetResponse обнаружило, что списки с двойным согласием были на 20–40% меньше, чем списки с одиночным согласием — и пользователи с опечатками математически гарантированно находятся в отсутствующих 20–40%, потому что они не могут получить письмо подтверждения по определению. Механизм обратный: письма подтверждения диагностируют проблему опечатки только после того, как пользователь уже потерян. Вы узнаёте об опечатке только когда само письмо подтверждения получает жёсткий отскок, к этому времени пользователь уже закрыл вкладку. Двойное согласие всё ещё имеет ценность для разрешения и фильтрации вовлечения. Это не, в каком-либо значимом смысле, слой обнаружения опечаток.

Нечёткое совпадение на стороне клиента ("Вы имели в виду gmail.com?") — это хороший UX, хрупкий как инфраструктура. Он требует поддержания словаря typo-domain, обработки интернационализированных доменов и избегания режима отказа, задокументированного Baymard Institute, в котором законные домены-коды стран или корпоративные TLD флагируются как опечатки. Словарь устаревает. Появляются новые паттерны опечаток. Полезно как слой UI поверх реального вызова верификации. Не замена для одного.
Проверки MX записей исключают несуществующие домены, но пропускают случаи опечатки-реального-домена. "gmial.com" — это зарегистрированный, MX-разрешаемый домен — вот именно почему это долгосрочная ловушка опечаток. Охотник за доменами хочет трафик. Проверки MX ловят вымышленные домены; они не ловят категорию опечаток, на которую этот материал. Проверка дешева и стоит запуска, но не принимайте прохождение её за реальный адрес.
API верификации в реальном времени объединяют все четыре слоя. Стандартная архитектура, задокументированная ZeroBounce и NeverBounce, работает синтаксис → MX → проба на уровне почтового ящика → флаг typo-domain → флаг disposable-domain в единственном вызове менее 500ms. Выход не логический pass/fail; это классифицированный вердикт, на который поток регистрации может разветвляться по-разному в зависимости от категории. Реальное валидирование адреса email возвращает эти сигналы как отдельные коды результата, что позволяет вам предлагать для опечаток, блокировать для одноразовых, и отклонять для недействительных без написания пяти независимых валидаторов.
Задержка не является возражением. Опубликованные времена отклика NeverBounce 100–500ms находятся ниже порога восприятия лага UI, особенно когда вызов срабатывает на размытие поля, а не на отправку. Пользователи уже переместили своё внимание на следующее поле; подсказка появляется, когда они взглянут назад.
Устойчивый к опечаткам поток регистрации в семи решениях
Архитектура ниже практична, не теоретична. Каждый элемент — это решение, которое команда принимает один раз и кодифицирует в путь кода регистрации. Рассуждение важнее конкретного синтаксиса — адаптируйте к вашему стеку.
- Валидируйте при размытии, не только при отправке. Запустите вызов верификации, когда поле email теряет фокус, чтобы подсказка появилась до того, как пользователь психически привязался к следующему полю. Исследование форм Nielsen Norman Group показывает, что встроенная валидация превосходит валидацию во время отправки для восстановления ошибок, потому что пользователь всё ещё ориентирован на поле, которое он только что оставил. Ошибки во время отправки требуют переориентации и ощущаются как наказание.
- Используйте ответ API с классифицированным вердиктом, не логический. Ответ должен разделить флаги typo, disposable, role account и invalid-mailbox, чтобы каждый мог вызвать различный UI. Логические ответы "is_valid" вынуждают вас выбрать одно лечение для пяти различных проблем, что является тем, как команды заканчивают блокировку восстанавливаемых пользователей. API поставщиков структурируют ответы таким образом по причине.
- Предложите, не автозаполните. Для флагов опечатки, отрендерите "Вы имели в виду john@gmail.com?" как одноразовое принятие. Молчаливое автозаполнение нарушает доверие пользователя — исследование e-commerce форм Baymard показывает, что пользователи отказываются, когда ловят поле, меняющееся под ними — и оно ломает законные краевые случаи, такие как корпоративные домены, которые выглядят как опечатки, но не.
- Блокируйте одноразовый отдельно от опечатки. Сигнал одноразового гарантирует жёсткую блокировку или понижение до гостевого уровня учётной записи с ограниченными функциями. Сигнал опечатки гарантирует мягкую подсказку с одноразовым исправлением. Рассмотрение обоих одинаково штрафует восстанавливаемых пользователей, в то время как недо-защищает против злоупотребления пробой. Стоимость ветвления — один дополнительный условный оператор.
- Отключите автозаполнение на слое ввода. Используйте
<input type="email" autocomplete="email" autocorrect="off" spellcheck="false">. Это предотвращает паттерн переопределения автозаполнения до любой валидации. Это изменение пяти атрибутов, которое устраняет весь класс опечаток. - Установите пороги жёсткого отскока и инструментируйте их. M3AAWG и Mailchimp оба рекомендуют, чтобы совокупные жёсткие отскоки оставались ниже 1% за кампанию, при 2% как зона опасности доставляемости. Оповещение на показателях отскока когорты-регистрации выше 1.5% — не только показателях по всей кампании. Отскок на уровне когорты — это ведущий индикатор того, что валидация на стороне захвата отказывает для конкретного источника, что средние показатели по всей кампании разбавляют.
- Логируйте паттерны опечаток и подавайте их обратно. Отслеживайте, какие домены ваши пользователи наиболее часто неправильно печатают. Если ваша аудитория производит повторяющийся паттерн "yaho.com" или ".cm", вы теперь знаете, где укрепить логику подсказки. Это закрывает цикл между обнаружением во время привлечения и текущей информацией о гигиене списка — и это позволяет вам измерить фактическую дельту из каждого изменения валидации, а не гадать.

Поток в целом требует одной интеграции API и горстки решений UI. Кумулятивная выгода состоит в том, что каждая последующая система — адаптация, биллинг, поддержка, маркетинг — работает на адресах, которые уже очищены от фильтров typo, disposable и invalid на границе. Вы прекращаете диагностирование проблем качества списка в панелях управления и начинаете их предотвращение в форме.
Что практики действительно спрашивают об опечатках в email
- Разве письмо подтверждения уже ловит опечатки? Нет — оно их диагностирует, но не ловит. Сравнение GetResponse одиночного vs двойного согласия обнаружило, что 20–40% пользователей никогда не подтверждают, и пользователи с опечатками математически гарантированно находятся в отсутствующей группе, потому что они не могут получить письмо подтверждения по определению. Вы узнаёте об опечатке только когда само письмо подтверждения получает жёсткий отскок, к этому времени пользователь уже закрыл вкладку и ушёл. Валидирование адреса email на стороне захвата в реальном времени выявляет опечатку, пока пользователь всё ещё на форме и может исправить её одним щелчком. Письма подтверждения остаются ценными для фильтрации разрешения и вовлечения — они доказывают, что пользователь действительно хотел получать вашу почту. Они не, механически, замена обнаружению опечаток при привлечении. Два слоя выполняют различные работы и должны сосуществовать.
- Если я автозаполню "gmial" на "gmail", я переопределяю намерение пользователя? Вы исправляете механическую ошибку ввода, не намеренный выбор — но только если вы подтверждаете с пользователем. Исследование e-commerce форм Baymard Institute показывает, что молчаливые исправления повреждают доверие и ломают краевые случаи, особенно корпоративные домены и региональные TLD, которые выглядят как опечатки, но не. Защищаемый паттерн — одноразовая подсказка: "Вы имели в виду john@gmail.com? [Да, используйте это] [Нет, оставьте мой]." Это сохраняет пользовательское агентство, в то время как делает исправление беспрепятственным. Пользователь сохраняет финальное решение, адрес с опечаткой восстанавливается в 95%+ случаев, когда подсказка правильна, и редкий законный краевой случай имеет чистый путь переопределения. Молчаливые переопределения оптимизируют неправильный метрик и производят худший опыт для длинного хвоста.
- В чём разница между адресом с опечаткой и одноразовым адресом — и почему это имеет значение? Опечатка — это законный пользователь с механической ошибкой; одноразовый — это пользователь активно избегающий отношений. Сигналы перекрываются ниже по течению — оба производят отскоки, оба снижают качество списка, оба повреждают доставляемость — но ответ при привлечении должен отличаться. Опечатки получают подсказку, потому что пользователь хочет входить. Одноразовые получают блокировку или понижение, потому что пользователь отказывается, выглядя при этом как одобрение. API в реальном времени, который флагирует их отдельно, позволяет вам маршрутировать каждый соответственно без написания двух параллельных валидаторов. Рассмотрение их идентично либо над-блокирует восстанавливаемых пользователей (если вы жёстко отклоняете опечатки вместе с одноразовыми), либо под-защищает против злоупотребления пробой (если вы только мягко предупреждаете одноразовые вместе с опечатками). Специализированный инструмент проверки одноразовых адресов email справляется с слоем обнаружения, специфичным для одноразовых; слой подсказки опечатки сидит поверх этого.
- Сколько моих регистраций действительно имеют опечатки прямо сейчас? Данные индустрии сходятся на 0.5–2% для аудиторий, ориентированных на рабочий стол B2B и 2–3%+ для мобильных приложений, ориентированных на потребителя, с набором данных из 4 миллиардов адресов ZeroBounce и исследованием typo-domain Kickbox как два наиболее цитируемых источника. Чтобы измерить вашу собственную базовую линию, а не угадывать: вытащите последние 90 дней регистраций, перекрёстно ссылайтесь на журнал жёсткого отскока вашего ESP и изолируйте отскоки, где домен находится на одной дистанции Левенштейна, отличная от основного провайдера (gmail, yahoo, hotmail, outlook, icloud, aol). Это подмножество — ваша текущая ставка опечаток. Запустите один и тот же запрос 30 дней спустя после развёртывания валидирования в реальном времени, чтобы измерить дельту чисто. До/после числа — единственные, которые имеют значение для обоснования интеграции внутри.
- Могу ли я построить обнаружение опечаток сам без API? Частично. Скрипт нечёткого совпадения на стороне клиента в отношении жёсткого кодированного списка распространённых typo доменов (gmial.com, yaho.com, hotnail.com, outlok.com, icould.com) ловит верхние 60–70% случаев с низкой стоимостью — расстояние Левенштейна ≤ 2 в отношении списка из 20 основных провайдеров охватывает удивительную долю объёма. Оставшиеся случаи требуют инфраструктуры: обработка путаницы TLD, обнаружение подмены поддомена, зонды на уровне почтового ящика, и постоянно обновляемый реестр typo-domain по мере появления новых паттернов. Порог build-vs-buy обычно находится в том, хочет ли ваша команда владеть поддержкой словаря, инфраструктурой проверки MX и зондами SMTP на уровне почтового ящика в перпетуитете. Для большинства команд путь API дешевле, чем задолженность по поддержке, и выгода предельного охвата на долгосрочных паттернах — это то место, где живёт действительный доход — не в верхних 60%, которые любой приличный скрипт справляет в день один.